




Dane strukturalne (schema.org) a widoczność treści w modelach AI
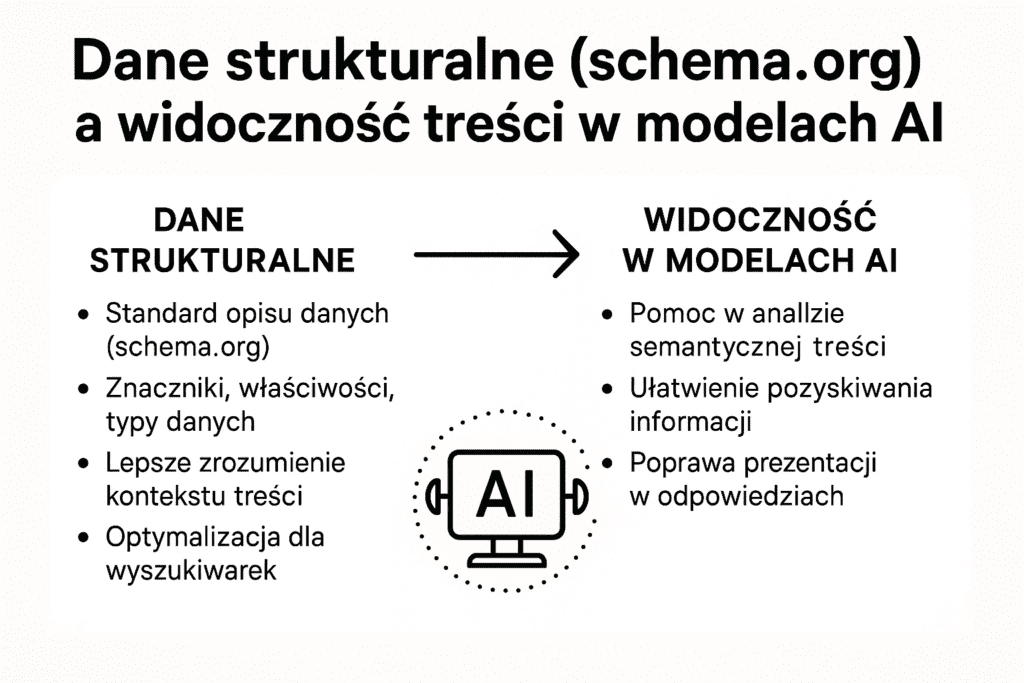
W świecie, w którym sztuczna inteligencja coraz częściej decyduje o tym, jakie treści użytkownicy zobaczą w wynikach wyszukiwania, dane strukturalne stają się coraz bardziej istotnym elementem strategii SEO. Jeszcze kilka lat temu ich główną rolą było ułatwienie Google’owi zrozumienia kontekstu strony – dziś jednak to właśnie one pozwalają modelom językowym, takim jak ChatGPT, Gemini czy Copilot, właściwie interpretować treści, nadawać im znaczenie i cytować je w odpowiedziach generatywnych.
Poniżej znajduje się przewodnik po danych strukturalnych. Zrozumienie zasad działania schema.org, umiejętne wdrożenie danych strukturalnych i utrzymanie ich spójności to obecnie coraz bardziej istotny element skutecznej widoczności marki w erze sztucznej inteligencji. W tym artykule przyjrzymy się, jak dane strukturalne w SEO mogą wpłynąć na interpretację treści przez modele AI oraz jakie typy Schema są najważniejsze i jak mogą wpłynąć na ruch w poszczególnych modelach LLM.
Czym właściwie są dane strukturalne i jak działają?
Czym jest schema? Dane strukturalne to specjalny sposób zapisu informacji na swojej stronie internetowej, który pomaga wyszukiwarkom oraz modelom sztucznej inteligencji lepiej zrozumieć, co dokładnie znajduje się w treści – czy jest to artykuł, produkt, recenzja, wydarzenie, oferta pracy czy profil firmy. W przeciwieństwie do klasycznego tekstu, który człowiek może interpretować intuicyjnie, algorytmy potrzebują jasnych i jednoznacznych wskazówek semantycznych. Dane strukturalne pełnią więc funkcję swoistego „tłumacza” między człowiekiem a maszyną, dzięki któremu systemy takie jak Google, Bing, ChatGPT, Copilot czy Gemini są w stanie prawidłowo przypisać kontekst, znaczenie i cel strony.
Technicznie dane te przyjmują formę kodu umieszczonego w strukturze strony – najczęściej w formacie JSON-LD (zalecanym przez Google), choć w niektórych projektach stosuje się też Microdata lub RDF. Przykładowo, jeśli prowadzisz lokalną firmę usługową, dane strukturalne pozwalają określić jej nazwę, adres, godziny otwarcia i dane kontaktowe. Dla sklepu internetowego – zdefiniują nazwę produktu, cenę, dostępność i opinię użytkowników. Dla bloga eksperckiego – umożliwią powiązanie artykułu z jego autorem, datą publikacji i źródłem.
W praktyce oznacza to, że poprawnie wdrożone dane strukturalne pomagają algorytmom AI rozpoznać Twoją stronę jako wiarygodne źródło informacji. To z kolei zwiększa szansę na pojawienie się w wynikach takich jak Google AI Overview, czy informacje o danej firmie w różnego rodzaju agentach LLM (jak np. ChatGPT). W nowym ekosystemie wyszukiwania, gdzie tradycyjna lista wyników ustępuje miejsca syntetycznym odpowiedziom generowanym przez modele językowe, czytelność danych strukturalnych staje się coraz bardziej istotnym warunkiem widoczności marki.
Różnica między klasycznym SEO a optymalizacją pod widoczność strony w AI
Jeszcze kilka lat temu pozycjonowanie stron skupiało się głównie na słowach kluczowych, linkach i strukturze witryny. Dziś jednak dominującą rolę w interpretacji treści odgrywa semantyka – czyli znaczenie, a nie tylko występowanie konkretnych fraz. Modele AI nie „czytają” treści tak, jak ludzie – one je analizują w kontekście powiązań między pojęciami, encjami i danymi z różnych źródeł. Właśnie dlatego dane strukturalne stały się nowym językiem SEO.
W klasycznym podejściu SEO dane strukturalne pomagały przede wszystkim w wyświetlaniu rozszerzonych wyników wyszukiwania (rich snippets) – ocen, gwiazdek, sekcje FAQ czy zdjęć produktów. W nowym ekosystemie wyszukiwania, gdzie treści są przetwarzane przez modele generatywne, ich rola staje się znacznie większa. Schema.org przede wszystkim może wpłynąć na lepsze zrozumienie kontekstu strony przez AI – a to oznacza, że Twoja firma ma większą szansę zostać przytoczona w odpowiedzi modelu, a nie tylko w wynikach Google.
Od rich snippets do odpowiedzi generatywnych: jak AI „czyta” dane strukturalne
Modele językowe uczą się na podstawie danych kontekstowych – a dane strukturalne dostarczają im tego kontekstu w sposób najbardziej precyzyjny. Dzięki schema.org, sztuczna inteligencja potrafi odróżnić np. recenzję od opisu produktu, a eksperta SEO od autora bloga kulinarnego.
W rezultacie treści oznaczone poprawnie danymi schema mogą być częściej cytowane przez modele generatywne, ponieważ systemy mogą traktować je jako bardziej wiarygodne i łatwiejsze do interpretacji.
Encje i kontekst – kluczowe pojęcia, które decydują o trafności cytowania w AI
Aby zrozumieć, jak modele sztucznej inteligencji „widzą” content strony, trzeba zapomnieć na chwilę o klasycznym SEO i słowach kluczowych. Dla AI nie liczy się to, jak często użyjesz frazy, ale czy system potrafi jednoznacznie zidentyfikować, o czym i o kim mówisz.
Tu właśnie wchodzą w grę encje (entities) – czyli rozpoznawalne pojęcia, osoby, miejsca, organizacje, produkty czy zdarzenia, które można jednoznacznie powiązać z określonym kontekstem.
Wyobraź sobie, że na stronie piszesz o JustIdea. Dla człowieka to oczywiste, że chodzi o agencję marketingową z Krakowa. Dla AI – już niekoniecznie. Model językowy musi zdecydować, czy „JustIdea” to nazwa marki, produktu, wydarzenia, a może po prostu opisowy zwrot. Dlatego więc, warto w schema.org jednoznacznie zdefiniować ten byt jako Organization lub LocalBusiness, a w jego ramach dodać dane takie jak adres, logo, strona internetowa czy profile społecznościowe, dzięki temu AI łatwiej rozpoznaje przypisanie marki do właściwej kategorii w grafie wiedzy.
Z technicznego punktu widzenia oznacza to, że encje działają jak węzły wiedzy połączone relacjami. Dane strukturalne (np. Article, Organization, LocalBusiness, Person, Product) pozwalają AI budować z tych węzłów sieć znaczeń.
Co ważne, Google i inne wyszukiwarki nie bazują już tylko na treści – roboty Google i AI analizują również relacje między encjami w wielu źródłach jednocześnie. Oznacza to, że spójność danych między Twoją stroną, profilami społecznościowymi, mapami Google i zewnętrznymi cytowaniami (np. katalogami firm) ma dziś bezpośredni wpływ na to, czy AI uzna Twoje treści za wiarygodne.
Czy schema.org to czynnik rankingowy, czy raczej „język” widoczności?
To pytanie zadaje sobie dziś większość specjalistów SEO i właścicieli stron: czy wdrożenie danych strukturalnych rzeczywiście poprawia pozycję w wynikach wyszukiwania?
Poprawnie wdrożone dane strukturalne działają jak „warstwa semantyczna” – pomagają Google i modelom AI zinterpretować, co dokładnie prezentujesz: czy to opis produktu, opinia, artykuł ekspercki, wizytówka firmy czy FAQ. Im bardziej zrozumiała i precyzyjna jest ta informacja, tym większe szanse, że Twoje dane zostaną wykorzystane w rich results, AI Overview, featured snippets czy odpowiedziach głosowych.
Trzeba jednak podkreślić, że sama obecność schema to nie wszystko. Google i inne systemy analizują również spójność danych strukturalnych z rzeczywistą treścią strony. Jeśli schema opisuje produkt, ale na stronie brakuje informacji o cenie lub zdjęcia, algorytm może uznać dane za niewiarygodne i je zignorować. Podobnie działa to w kontekście AI — model językowy nie wykorzysta danych, które nie mają potwierdzenia w realnym kontekście treści.
W praktyce – brak danych strukturalnych nie sprawi, że strona zanotuje spadek widoczności, ale ich obecność może sprawić, że Twoja zawartość strony zostanie zrozumiana i zauważona tam, gdzie inni pozostaną niewidoczni.
Kluczowe typy danych strukturalnych zwiększające widoczność treści w AI
Dane strukturalne można wdrożyć na wiele sposobów, ale nie wszystkie typy schema.org mają taki sam wpływ na widoczność treści w systemach opartych na sztucznej inteligencji. Poniżej, przedstawię moim zdaniem 5 najbardziej popularnych elementów Schema: Article, FAQPage, Product, LocalBusiness oraz Organization.
Każdy z nich odpowiada za inny aspekt widoczności.
Schema Article
Schema Article to podstawowy typ danych strukturalnych dla wszelkich treści blogowych, edukacyjnych, branżowych i eksperckich. Jego zadaniem jest jednoznaczne określenie, że dana strona zawiera artykuł — czyli materiał informacyjny, napisany przez konkretnego autora, opublikowany przez konkretną markę, w określonym czasie i kontekście.
Dzięki Article modele AI potrafią rozpoznać charakter publikacji, powiązać autora z organizacją. To kluczowe w kontekście AI Overviews, które coraz częściej cytują artykuły branżowe i poradnikowe z dobrze opisanych stron.
W praktyce dane strukturalne typu Article powinny zawierać:
- tytuł (headline),
- autora (author → Person lub Organization),
- datę publikacji (datePublished),
- oraz odniesienie do adresu URL artykułu (mainEntityOfPage).
Przykład JSON-LD:
Schema FAQPage
Schema FAQPage (FAQ Schema) opisuje strony zawierające sekcje pytań i odpowiedzi. Jeszcze kilka lat temu służyła głównie do uzyskania rozszerzeń w wynikach wyszukiwania (rich results), ale dziś — pomaga modelom AI szybciej identyfikować treści odpowiadające na konkretne pytania.
FAQPage świetnie sprawdza się w artykułach poradnikowych, czy na stronach ofertowych, gdzie treść odpowiada na konkretne pytania użytkowników. Dobrze wdrożony FAQPage zwiększa szanse, że fragmenty treści zostaną zacytowane w AI Overviews lub przywołane w tzw. „People Also Ask”. Używaj FAQPage tylko tam, gdzie faktycznie istnieje sekcja pytań i odpowiedzi. Google coraz częściej weryfikuje spójność między schema a widoczną treścią — jeśli schema nie ma potwierdzenia w HTML, może zostać zignorowana.
Przykład JSON-LD:
Schema Product
Schema Product to filar danych strukturalnych dla e-commerce. Dzięki niemu wyszukiwarki i modele AI mogą rozpoznać: cenę, typ produktu, dostępność, producenta oraz opinie użytkowników. Modele językowe (np. w Copilot czy Perplexity) mogą generować rekomendacje produktów na podstawie oznaczonych danych.
Modele AI analizują te dane, by dopasować produkty do zapytań użytkowników („najlepszy zestaw do kawy do 300 zł”) – dobrze opisana Schema Product zwiększa szanse, że Twoja oferta pojawi się w wynikach AI.
Przykład JSON-LD:
Schema LocalBusiness – fundament dla biznesów lokalnych w erze sztucznej inteligencji
Dla firm działających lokalnie (gabinetów, restauracji, salonów, kancelarii, agencji, sklepów stacjonarnych) schema LocalBusiness to absolutna podstawa. Dzięki niemu Google, Bing, ChatGPT czy Gemini potrafią lepiej powiązać nazwę firmy, adres, godziny otwarcia i dane kontaktowe z konkretną lokalizacją w świecie rzeczywistym.
To właśnie schema LocalBusiness wspiera to, że Twoja marka pojawia się w mapach Google, wynikach lokalnych („near me”, „w pobliżu”), a także w wynikach generatywnych, które coraz częściej wykorzystują dane geolokalizacyjne. Dobrze opisana Schema LocalBusiness zwiększa szansę, że AI wybierze Twoją firmę jako odpowiedź dla zapytań kontekstowych, np. „agencja marketingowa w Krakowie specjalizująca się w SEO” lub „najlepszy salon fryzjerski w Krakowie otwarty w soboty”.
Aby schema LocalBusiness działała poprawnie, musi zawierać kilka obowiązkowych elementów:
- nazwę firmy (name),
- adres (address → PostalAddress),
- numer telefonu (telephone),
- godziny otwarcia (openingHours),
- oraz opcjonalnie linki do profili społecznościowych (sameAs).
Przykład JSON-LD:
Dane z tego schema powinny być identyczne z tymi w Twoim profilu Google Business Profile (dawniej Google Moja Firma). AI może zweryfikować spójność informacji między źródłami.
Ponadto warto dodać geo (koordynaty geograficzne), co ułatwia powiązanie lokalizacji z zapytaniami użytkowników. Dla biznesów wielolokalizacyjnych możliwe jest wdrożenie kilku schematów LocalBusiness – po jednym na każdą filię lub oddział.
Schema Organization – jak buduje wiarygodność marki i autorytet źródła
Schema Organization jest jednym z najważniejszych, ale jednocześnie najczęściej pomijanych elementów danych strukturalnych. Właśnie on pomaga Google i modelom AI zrozumieć, kto stoi za publikowanymi treściami, kto jest właścicielem domeny i jaka organizacja odpowiada za jej wiarygodność.
W erze sztucznej inteligencji, gdzie modele generatywne uczą się nie tylko na podstawie treści, ale też reputacji źródła, Schema Organization pełni funkcję cyfrowego certyfikatu tożsamości marki.
Dzięki niemu systemy potrafią połączyć nazwę firmy z jej logo, siedzibą, stroną internetową, profilem na LinkedIn czy kanałem YouTube. W efekcie Twoja marka jest rozpoznawana jako realny podmiot w grafie wiedzy (Knowledge Graph), co znacząco zwiększa szanse na cytowania i pojawienie się w tzw. entity panels lub AI Overviews.
Ważne jest również, by schema Organization był powiązany z innymi schematami na stronie – np. z Article (poprzez publisher) lub LocalBusiness (jeśli firma ma lokalną siedzibę). Taka sieć relacji buduje spójność semantyczną, którą AI traktuje jako sygnał autorytetu.
Przykład JSON-LD:
Kiedy modele AI przetwarzają treści, często analizują „źródła zaufania”. Strony posiadające pełne dane Organization mogą być traktowane jako wiarygodne źródła autorskie, co może mieć bezpośredni wpływ na widoczność w odpowiedziach generatywnych. W praktyce, to właśnie dzięki Schema Organization marki pojawiają się w AI Overviews obok nazw ekspertów i publikacji branżowych.
Wdrożenie danych strukturalnych – praktyczne wskazówki i dobre praktyki
JSON-LD, Microdata czy RDFa – który format wybrać i dlaczego?
Zanim przystąpimy do wdrażania danych strukturalnych, warto zrozumieć, że schema.org nie jest pojedynczym standardem, lecz zbiorem definicji, które można wdrażać w różnych formatach technicznych.
Najpopularniejsze z nich to JSON-LD, Microdata i RDFa. Wszystkie pozwalają wyszukiwarkom zrozumieć strukturę strony, ale różnią się sposobem implementacji, elastycznością i odpornością na błędy.
JSON-LD – rekomendowany przez Google i najłatwiejszy w utrzymaniu
JSON-LD (JavaScript Object Notation for Linked Data) to obecnie standard branżowy, oficjalnie rekomendowany przez Google i największe wyszukiwarki.
Jego największą zaletą jest to, że dane są oddzielone od treści HTML – dodajesz je w jednym fragmencie kodu (zazwyczaj w <head> lub na końcu <body>), co sprawia, że łatwo je aktualizować, testować i wdrażać masowo.
JSON-LD świetnie sprawdza się w dynamicznych środowiskach (WordPress, Shopify, Webflow, React, Next.js), gdzie front-end jest często modyfikowany.
Dzięki niezależności od struktury HTML, nawet duże zmiany w wyglądzie strony nie wpływają na działanie markupu.
Microdata – dobry na start, ale trudny w utrzymaniu
Microdata była popularna w czasach, gdy strony były statyczne, a dane strukturalne oznaczało się bezpośrednio w treści HTML.
W tym formacie informacje dodaje się poprzez atrybuty itemprop, itemscope i itemtype – czyli dosłownie „opakowuje się” fragmenty tekstu w znaczniki semantyczne.
Choć dla małych witryn może to być wygodne rozwiązanie, przy większych projektach (zwłaszcza z nowoczesnym frontem lub komponentami) Microdata staje się trudna w utrzymaniu.
Każda zmiana w strukturze HTML może uszkodzić dane, a debugowanie błędów jest bardziej czasochłonne niż w JSON-LD.
RDFa – dla zaawansowanych projektów semantycznych
RDFa (Resource Description Framework in Attributes) to najbardziej elastyczna i precyzyjna forma zapisu danych strukturalnych, używana głównie w dużych projektach badawczych, edukacyjnych lub encyklopedycznych.
Pozwala tworzyć bardzo złożone relacje między encjami i odwoływać się do wielu kontekstów jednocześnie.
Jednak w praktyce biznesowej — np. w SEO dla firm czy e-commerce — jest stosunkowo rzadko spotykana, ponieważ jej implementacja wymaga dużej precyzji i znajomości semantyki RDF.
Jak sprawdzić poprawność schema w Google Rich Results Test i Search Console?
Wdrożenie danych strukturalnych to dopiero pierwszy krok. Kolejnym — i równie istotnym — jest walidacja poprawności Schemy.
Błędy w strukturze JSON-LD, literówki w nazwach pól, brak wymaganych atrybutów czy niespójność z rzeczywistą treścią mogą sprawić, że dane strukturalne zostaną przez Google i modele AI całkowicie zignorowane.
Dlatego każdy wdrożony fragment Schema należy przetestować.
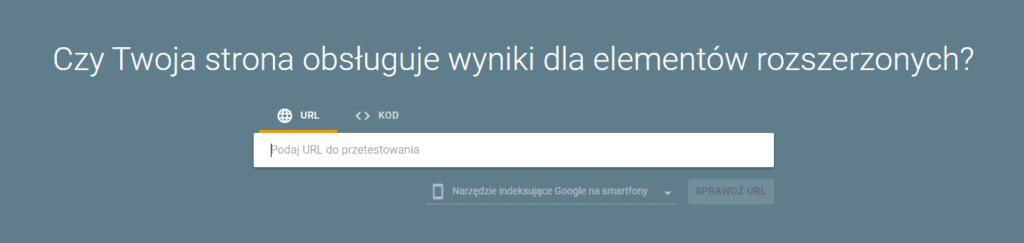
1. Google Rich Results Test – podstawowe narzędzie weryfikacyjne
Najprostszym i najbardziej intuicyjnym sposobem na sprawdzenie poprawności schema jest narzędzie Google Rich Results Test.
Pozwala ono sprawdzić zarówno pojedynczy adres URL, jak i fragment kodu JSON-LD, Microdata lub RDFa.
Jak to działa:
-
Wklejasz link do strony lub kod markupu.
-
Google analizuje dane, wskazuje, jakie typy schema zostały rozpoznane (np. Article, FAQPage, Product).
-
Otrzymujesz raport zawierający błędy (Errors) i ostrzeżenia (Warnings).
Błędy – to elementy, które uniemożliwiają poprawne zrozumienie danych (np. brak pola name w Product).
Ostrzeżenia – nie blokują działania schema, ale informują, że brakuje opcjonalnych, rekomendowanych pól (np. brak aggregateRating).
To narzędzie ma ogromną zaletę — możesz wklejać kod jeszcze przed wdrożeniem na stronie, dzięki czemu od razu wiesz, czy schema jest poprawna i gotowa do publikacji.
Wyniki walidacji pokazują też, czy dane są kwalifikowane do Rich Results (rozszerzonych wyników), co pośrednio potwierdza, że markup został dobrze rozpoznany przez systemy Google.
2. Google Search Console – analiza wdrożonych danych w praktyce
Po wdrożeniu schema warto przejść do Google Search Console (GSC), która monitoruje wdrożone dane strukturalne na całej domenie.
W sekcji „Ulepszenia” (Enhancements) znajdziesz osobne raporty dla różnych typów danych — np. FAQ, Product, Article, Breadcrumb, LocalBusiness itd.
Raport GSC pokazuje:
- liczbę stron z poprawnymi danymi,
- liczbę stron z błędami,
- liczbę stron z ostrzeżeniami,
- oraz trend zmian w czasie (czy błędów przybywa, czy ubywa).
Dzięki temu możesz śledzić, czy wdrożony schema działa prawidłowo i czy po aktualizacjach front-endu nie pojawiły się nowe błędy.
Warto pamiętać, że błędy w GSC nie zawsze pojawiają się natychmiast — czasem Google potrzebuje kilku dni, by ponownie zindeksować stronę i zaktualizować raport.
Jeśli widzisz w GSC ostrzeżenia (warnings), ale nie błędy — nie panikuj. To tylko sugestie optymalizacji, a nie powód do odrzucenia schema.
Błędy natomiast (errors) wymagają poprawy, bo mogą powodować, że dane nie są analizowane przez systemy Google ani modele AI.
3. Testy alternatywne i manualna inspekcja w kodzie strony
Oprócz oficjalnych narzędzi Google warto korzystać także z:
- Schema Markup Validator – analiza zgodności ze standardem schema.org,
- Ahrefs / Semrush / Screaming Frog – do automatycznego wykrywania i audytu schema w dużych serwisach,
- Manualna inspekcja w kodzie źródłowym (Ctrl+U / Ctrl+F → „ld+json”)
Jakie są najczęstsze błędy we wdrażaniu schema.org i jak ich uniknąć?
Wielu marketerów i deweloperów zakłada, że jeśli dane strukturalne przechodzą walidację w narzędziach Google, to wszystko jest w porządku. Niestety, to tylko połowa prawdy.
Google Rich Results Test potwierdza jedynie poprawność techniczną — ale nie to, czy dane mają sens, są spójne z treścią i użyteczne dla modeli AI.
W efekcie wiele stron z wdrożonym schema.org nadal nie zyskuje widoczności w wynikach ani nie pojawia się w odpowiedziach generatywnych.
Przyjrzyjmy się więc najczęstszym błędom i sposobom, jak ich uniknąć.
Jakie są najczęstsze błędy we wdrażaniu danych strukturalnych i jak ich unikać?
1. Brak spójności między schema a rzeczywistą treścią strony
To najczęstszy i zarazem najpoważniejszy błąd. Dane strukturalne muszą w pełni odzwierciedlać treść widoczną dla użytkownika. Jeśli w schema Product pojawia się inna cena niż ta podana na stronie, w schema LocalBusiness inny adres niż w stopce, lub w FAQ znajdują się pytania, których fizycznie nie ma w treści, Google uznaje to za manipulację semantyczną.
Aby uniknąć tego błędu, warto generować dane strukturalne z tych samych źródeł co treść – np. bezpośrednio z CMS-a, bazy danych lub API. Po wdrożeniu zawsze należy porównać markup z kodem HTML (np. w widoku źródła strony) i upewnić się, że schematy uzupełniają treść, a nie próbują jej zastąpić.
2. Duplikacja lub nakładanie się typów schema
To problem szczególnie powszechny wśród użytkowników automatycznych wtyczek SEO, takich jak Yoast, RankMath czy SEOPress. Narzędzia te często generują automatycznie dane typu Article, WebPage lub BlogPosting, co prowadzi do konfliktu i duplikacji. W takiej sytuacji Google wybiera losowo jeden z typów, ignorując pozostałe, przez co strona traci kontekst semantyczny. Aby tego uniknąć, należy pamiętać, że na jednej stronie nie powinno być dwóch Article ani dwóch Organization.
3. Stosowanie przestarzałych lub błędnych właściwości
Schema.org jest nieustannie aktualizowane, dlatego korzystanie ze starych pól lub niewłaściwych typów może prowadzić do błędnej interpretacji danych przez wyszukiwarki i modele AI. Wiele firm wciąż stosuje właściwości, które zostały wycofane lub zastąpione nowymi. Aby tego uniknąć, warto regularnie sprawdzać aktualną dokumentację schema.org, zwłaszcza sekcję Pending Schemas i Deprecations, oraz korzystać z oficjalnych przykładów Google. Każdy wdrożony schemat należy przetestować w narzędziu Rich Results Test, zanim trafi na stronę.
4. Umieszczanie zbyt wielu schematów na jednej stronie
Niektórzy próbują zwiększyć widoczność, dodając jak najwięcej typów schema na jednej stronie, co prowadzi do chaosu semantycznego. Google preferuje klarowny i jednowątkowy kontekst – przykładowo, na stronie artykułu powinien znajdować się jeden główny Article, a nie zestaw Article, Product, FAQPage i Event. Najlepszą praktyką jest dobieranie schematów zgodnie z przeznaczeniem strony: dla bloga – Article, dla oferty – Product lub Service, a dla podstrony lokalizacyjnej – LocalBusiness. Jeśli konieczne jest łączenie różnych kontekstów, należy robić to poprzez linkowanie między stronami, a nie wewnątrz jednego schematu.
5. Brak aktualizacji po zmianach w treści
Schema nie jest elementem typu „dodaj raz i zapomnij”. Zmiana tytułu artykułu, nazwy produktu, adresu firmy czy godzin otwarcia wymaga aktualizacji danych strukturalnych. Nieaktualne schematy są sygnałem niskiej jakości, a w skrajnych przypadkach mogą zostać potraktowane jako próba manipulacji. Każda modyfikacja treści powinna automatycznie wiązać się z aktualizacją odpowiedniego schematu.
Jak dane strukturalne wspierają SEO lokalne i e-commerce?
Wdrożenie danych strukturalnych (schema.org) to sposób, który może wpłynąć na zwiększenie widoczności, wiarygodności i konwersji w wyszukiwarkach opartych na sztucznej inteligencji. Dobrze przygotowana Schema może nie tylko wpłynąć na lepsze zrozumienie treści Twojej strony, ale także wyróżnić ją w wynikach — zarówno klasycznych, jak i generatywnych (AI Overviews, wyszukiwanie głosowe, Copilot, Perplexity).
Korzyści dla SEO lokalnego
- Większa widoczność w wynikach lokalnych i mapach Google – schema LocalBusiness pomaga powiązać nazwę firmy, adres, godziny otwarcia i lokalizację z rzeczywistym miejscem.
- Wiarygodność marki w oczach AI – spójne dane (na stronie, w Google Business Profile, mediach społecznościowych) potwierdzają tożsamość firmy i zwiększają zaufanie modeli AI.
- Obecność w wynikach głosowych i AI Overviews – dobrze opisane dane pozwalają sztucznej inteligencji łatwiej rekomendować Twoją firmę jako odpowiedź na zapytania typu „najbliższy salon kosmetyczny otwarty teraz”.
- Lepsze dopasowanie do zapytań użytkowników – schema pomaga AI zrozumieć, czym się zajmujesz i komu oferujesz swoje usługi, co poprawia trafność wyników.
Korzyści dla e-commerce
- Większy CTR dzięki rich snippets – gwiazdki, ceny, dostępność produktów i opinie zwiększają atrakcyjność wyników w Google, co może przełożyć się na wyższy współczynnik kliknięć.
- Wyższa konwersja dzięki zaufaniu użytkowników – dane o ocenach, marce i dostępności produktów budują wiarygodność i wpływają na decyzje zakupowe.
- Lepsza widoczność w rekomendacjach AI – modele generatywne mogą chętniej cytować i rekomendować produkty z kompletnym schema Product, Offer i Review.
- Pozycjonowanie marek niszowych – nawet mniejsze sklepy mogą konkurować z dużymi platformami, jeśli dostarczają AI kompletne i poprawne dane strukturalne.
Jak unikać niespójnych encji i błędów semantycznych?
Encje (entities) to podstawowe „jednostki znaczenia”, którymi posługują się modele AI.
Każda firma, produkt, osoba czy miejsce to osobna encja — i każda z nich powinna być jednoznacznie opisana.
Problem pojawia się wtedy, gdy dane dotyczące marki są rozproszone, niespójne lub sprzeczne.
Przykład:
- Na stronie schema LocalBusiness podaje adres „ul. Piękna 12”,
- w stopce strony widnieje „ul. Piękna 11”,
- a w profilu Google Business Profile – „ul. Piękna 10”.
Dla człowieka to drobnostka. Dla AI – trzy różne encje, a więc trzy potencjalnie różne firmy.
W efekcie system nie wie, którą informację uznać za prawdziwą.
Aby uniknąć tych błędów, należy pamiętać o:
- o ujednoliceniu nazwy firmy, adresu, numeru NIP, numeru telefonu oraz adresów URL na wszystkich platformach, takich jak strona internetowa, Google Maps, LinkedIn, katalogi branżowe czy media społecznościowe,
- o stosowaniu tych samych informacji we wszystkich danych dotyczących firmy, tak aby zachować pełną spójność między źródłami,
- o przygotowaniu osobnego zestawu danych strukturalnych dla każdej lokalizacji, zamiast duplikowania tych samych informacji dla różnych oddziałów,
- o regularnym aktualizowaniu danych po każdej zmianie adresu, rebrandingu lub przeniesieniu siedziby, by uniknąć niespójności w interpretacji marki przez wyszukiwarki i modele AI.
AI działa logicznie, nie intuicyjnie. Jeśli coś nie jest jednoznaczne, traktuje to jako niepewne źródło.
Budowanie autorytetu źródła poprzez dane strukturalne i linkowanie semantyczne
Autorytet w kontekście AI nie polega tylko na liczbie linków, ale na semantycznym powiązaniu encji.
Oznacza to, że jeśli Twoja strona, profil autora, firma i produkt są połączone logicznie w schema.org, AI widzi to jako spójną sieć wiedzy – a nie zbiór przypadkowych informacji.
Modele językowe tworzą tzw. knowledge graph, czyli sieć powiązań między pojęciami, markami i osobami.
Im bardziej spójnie Twój ekosystem jest opisany, tym większe szanse, że AI zrozumie Twoją markę jako wiarygodne źródło wiedzy i będzie cytować Twoje treści w odpowiedziach generatywnych.
Najczęstsze pytania o dane strukturalne i widoczność w AI (FAQ)
Czy schema.org ma wpływ na pozycje w AI Overviews?
Treści z dobrze wdrożonym schema.org mogą być częściej cytowane w AI Overviews, ponieważ modele mogą łatwiej je interpretować, przypisywać do właściwych encji i oceniać jako wiarygodne źródła.
Czy każda strona powinna mieć sekcję FAQPage?
Nie każda — ale każda, która odpowiada na pytania użytkowników, powinna.
Schema FAQPage działa najlepiej w treściach edukacyjnych, ofertowych lub poradnikowych, gdzie faktycznie istnieją pytania i odpowiedzi.
Jeśli dodasz FAQPage tam, gdzie nie ma faktycznych treści w formie pytań, Google może uznać dane za nadużycie schema i zignorować je.
Czy błędne schema może zaszkodzić widoczności treści?
Błędy w schema (np. brak wymaganych pól, niespójność z treścią, nieaktualne dane) mogą sprawić, że cały markup zostanie odrzucony przez Google.
Co gorsza, powtarzające się błędy techniczne mogą obniżyć wiarygodność witryny w kontekście AI, które interpretuje takie dane jako „niepewne źródło”.
Przykład:
Jeśli schema Product podaje cenę 249 zł, a na stronie widnieje 199 zł, model AI uzna dane za niespójne i pominie stronę przy generowaniu rekomendacji.
Dlatego po każdym wdrożeniu lub aktualizacji treści należy przeprowadzić walidację schema w narzędziu Google Rich Results Test oraz weryfikację w Search Console.
Czy plik llms.txt jest obowiązkowy?
Plik llms.txt to eksperymentalny standard, nad którym pracują m.in. OpenAI i Google, by umożliwić właścicielom stron decydowanie, czy ich treści mogą być używane do trenowania modeli językowych.
Warto śledzić jego rozwój, ponieważ w perspektywie kilku lat llms.txt może działać w parze z danymi strukturalnymi — określając, które fragmenty wiedzy mogą być indeksowane i cytowane przez modele generatywne.
Czy dane strukturalne wpływają na CTR?
Rich Snippets (gwiazdki, ceny, FAQ, dostępność produktów) mogą poprawić współczynnik CTR (klikalność) danego wyniku wyszukiwania.
Co warto zapamiętać – dane strukturalne jako most między SEO a AI
Dane strukturalne stały się filarem widoczności w nowoczesnym ekosystemie wyszukiwania. Schema.org to dziś nie opcja, lecz obowiązek dla każdej marki, która chce być rozumiana przez wyszukiwarki i modele sztucznej inteligencji. Właściwie wdrożone schematy — takie jak Organization, Article, Product, LocalBusiness czy FAQPage — tworzą semantyczną sieć wiedzy, dzięki której Twoja marka przestaje być anonimową stroną w internecie, a staje się rozpoznawalną jednostką wiedzy.
Kluczem do sukcesu jest spójność danych. AI nie ufa źródłom, które przekazują sprzeczne informacje. Jeśli Twoje schema, profile społecznościowe i treści mówią jednym głosem — budujesz cyfrowe zaufanie. Jeden adres, jedna nazwa, jedno logo, jedna tożsamość marki. W świecie generatywnej sztucznej inteligencji to właśnie spójność encji jest nową walutą zaufania.
W perspektywie kilku lat schema.org stanie się integralną częścią sposobu, w jaki AI rozumie świat. Modele językowe nie czytają treści tak jak ludzie — one uczą się z relacji. Jeśli Twoja strona jest logicznie opisana, spójna i semantycznie powiązana, stajesz się częścią globalnego ekosystemu wiedzy.
To już nie tylko walka o pozycję w Google — to walka o zrozumienie przez sztuczną inteligencję.
Zadbaj o swoją widoczność w erze AI
Jeśli chcesz, by Twoja marka była widoczna, rozumiana i cytowana przez sztuczną inteligencję — zacznij od fundamentów.
W JustIdea pomagamy firmom wdrażać dane strukturalne, budować spójność semantyczną i zwiększać widoczność w wynikach AI.
Sprawdź również
- Jak często analizować treści SEO?
- Czym jest PrestaShop? Kompletny przewodnik
- Topical Relevance – sekret skutecznej strategii content marketingowej
- Jak pozycjonować wizytówkę Google?





















