




Jak rozwiązać problem indeksowania stron w Google? Znamy rozwiązanie!
Czy zastanawiałeś się kiedyś, dlaczego Twoja strona internetowa nie pojawia się w wynikach wyszukiwania Google, mimo że poświęciłeś mnóstwo czasu i energii na jej optymalizację? Nie jesteś sam! W dzisiejszym świecie, gdzie obecność online jest kluczowa dla sukcesu danego biznesu, nieobecność w wyszukiwarce Google może być frustrująca i kosztowna. Ale nie martw się, mamy rozwiązanie!
W tym artykule przyjrzymy się głównym przyczynom, „dlaczego Google nie wyszukuje mojej strony„, oraz przedstawimy sprawdzone metody, które pomogą Ci poprawić indeksowanie strony w Google. Czytaj dalej, aby odkryć, jak rozwiązać problem niewidoczności Twojej strony w Google i zacząć przyciągać więcej ruchu na swoją stronę internetową już dziś!
Indeksowanie – co to znaczy?
Czym jest indeksowanie? Aby zrozumieć, dlaczego Twoja strona nie pojawia się w wynikach wyszukiwania Google, najpierw musimy zgłębić proces, który stoi za tym mechanizmem: indeksowanie.
Indeksowanie to kluczowy etap działania wyszukiwarek, który umożliwia Twojej stronie internetowej znalezienie się w bazie danych Google. Proces ten polega na przeszukiwaniu (crawling) stron internetowych przez specjalne oprogramowanie znanego jako roboty wyszukiwarek (np. Googlebot), analizowaniu ich treści, a następnie dodawaniu do ogromnego indeksu, który jest wykorzystywany do wyświetlania wyników wyszukiwania.
Jak to działa? Roboty wyszukiwarek regularnie przeszukują Internet w poszukiwaniu nowych stron, aktualizacji istniejących stron oraz linków prowadzących do kolejnych zasobów. Po odwiedzeniu strony, roboty analizują jej zawartość, strukturę oraz metadane, takie jak tagi tytułów, opisy meta, nagłówki, a także zawartość tekstową i multimedialną. Informacje te są następnie przechowywane w indeksie wyszukiwarki.
Dlaczego indeksowanie jest tak ważne? Bez indeksowania, Twoja strona internetowa jest niewidoczna dla Google, a co za tym idzie – nie może być wyświetlana użytkownikom wyszukiwarki. Proces indeksowania jest więc pierwszym krokiem do zbudowania widoczności w Internecie i kluczowym elementem strategii SEO, pozycjonowania, której celem jest poprawa pozycji strony w wynikach wyszukiwania.
W następnych sekcjach przyjrzymy się bliżej, co może zaburzać proces indeksowania Twojej strony i jak możemy temu zaradzić, aby zwiększyć jej widoczność online.
Jak sprawdzić czy moja strona się indeksuje?
Upewnienie się, czy Twoja strona jest indeksowana przez Google, jest pierwszym krokiem do zdiagnozowania i rozwiązania problemów z widocznością w wyszukiwarce. Istnieje kilka metod, które pomogą Ci szybko zweryfikować status indeksacji Twojej witryny. W kolejnych sekcjach artykułu przyjrzymy się każdej z metod bardziej szczegółowo, aby pomóc Ci zrozumieć, jak efektywnie korzystać z dostępnych narzędzi do monitorowania i poprawy widoczności Twojej strony w Google.
Dlaczego moja strona się nie indeksuje?
Brak indeksacji strony w Google może być wynikiem wielu różnych czynników, które wpływają na to, jak wyszukiwarki odbierają i przetwarzają treść Twojej strony. Poniżej przedstawiamy najczęstsze przyczyny, dla których Twoja strona internetowa może nie być indeksowana, oraz wskazówki, jak zidentyfikować i rozwiązać te problemy.
Rozwiązanie problemów z indeksacją wymaga zrozumienia i adresowania konkretnych przyczyn, dla których Twoja strona może nie być widoczna dla wyszukiwarek. Regularne monitorowanie i optymalizacja strony pod kątem SEO są kluczowe dla utrzymania jej zdrowia i widoczności w internecie.
Stan indeksacji: użycie wyszukiwania z operatorem „site:domena.pl”
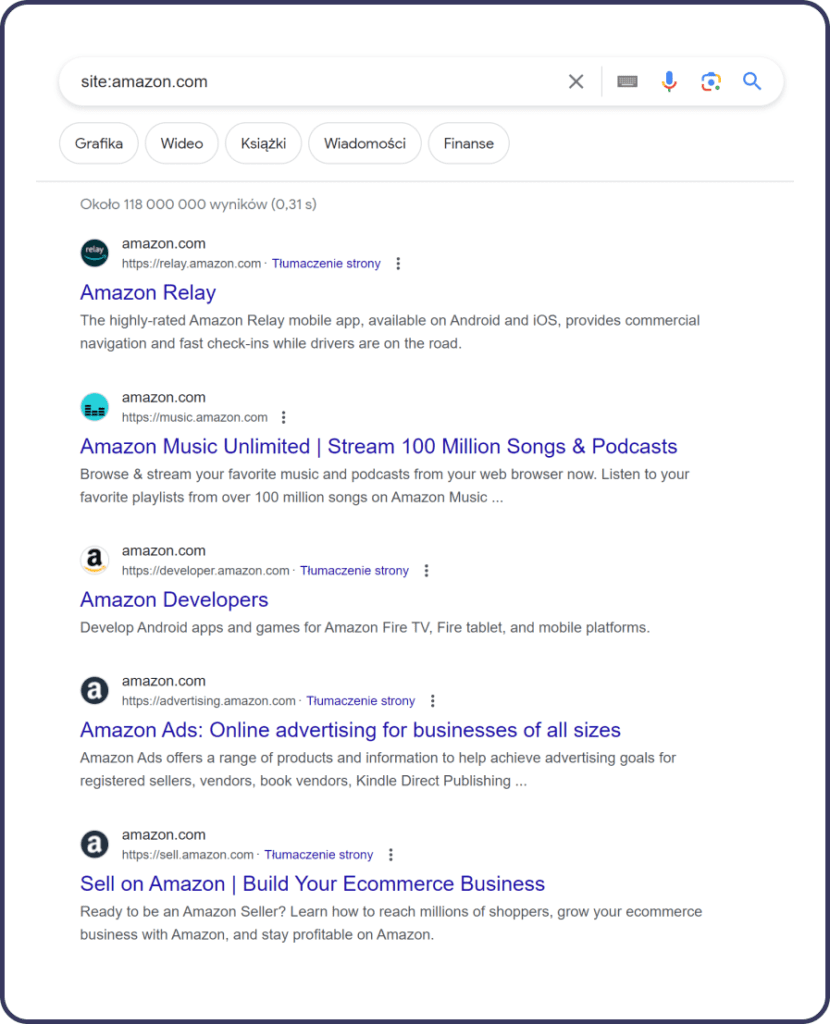
Jednym z najprostszych i najbardziej bezpośrednich sposobów na sprawdzenie, czy Twoja strona jest indeksowana przez Google, jest użycie wyszukiwania z operatorem „site:”. Ta metoda pozwala szybko zweryfikować, które strony z Twojej witryny zostały już dodane do indeksu Google. Aby to zrobić, wystarczy wykonać proste wyszukiwanie w Google, używając następującego formatu:
Zastąp „twojadomena.pl” rzeczywistym adresem URL Twojej strony. Po wprowadzeniu tego zapytania, Google wyświetli listę wszystkich stron z Twojej witryny, które znajdują się w jego indeksie. Jeśli wyniki się pojawią, oznacza to, że Twoja strona jest indeksowana. Brak wyników może wskazywać na problemy z indeksacją.
Dlaczego to ważne? Użycie tego operatora jest szybkim sposobem na sprawdzenie podstawowego stanu indeksacji Twojej witryny. Możesz również użyć tego narzędzia do monitorowania, jak szybko nowe strony są dodawane do indeksu Google, a także do identyfikacji stron, które mogły zostać pominięte.
Google Search Console – stan indeksu
Google Search Console (GSC) to nieocenione narzędzie dla każdego właściciela strony internetowej, które dostarcza szczegółowych informacji na temat sposobu, w jaki Google widzi i indeksuje Twoją stronę. To narzędzie oferuje bogaty zestaw funkcji, które pomagają monitorować i poprawiać widoczność Twojej strony w wynikach wyszukiwania. Jedną z kluczowych funkcji jest możliwość sprawdzenia stanu indeksu Twojej strony.
Jak korzystać z Google Search Console do sprawdzania indeksu?
- Zweryfikuj swoją witrynę w GSC: Aby uzyskać dostęp do danych Twojej strony, musisz najpierw dodać i zweryfikować swoją witrynę w Google Search Console. Proces weryfikacji potwierdza, że jesteś właścicielem strony.
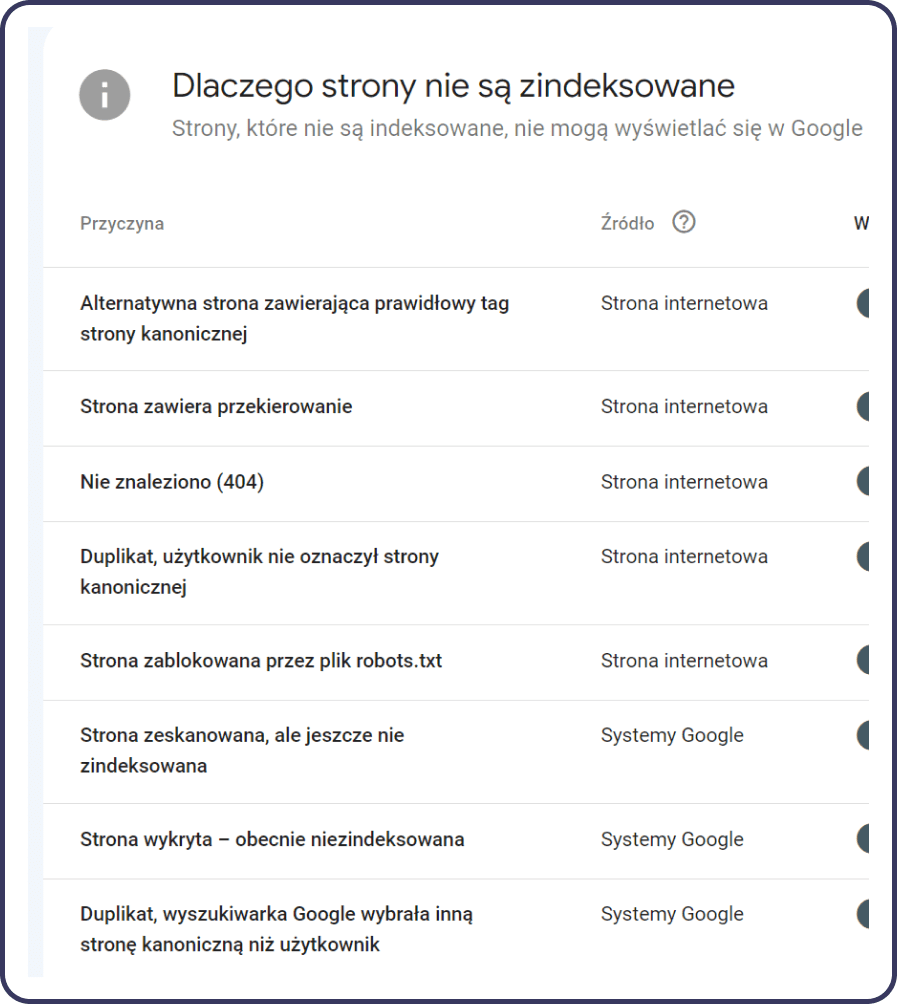
- Sprawdź raport „Indeksowanie”: Po pomyślnej weryfikacji, przejdź do raportu „Indeksowanie stron” w GSC. Ten raport dostarcza szczegółowych informacji o statusie indeksacji Twojej strony, wskazując, które strony zostały zaindeksowane, a które napotkały błędy lub ostrzeżenia podczas procesu indeksowania.
- Analiza i rozwiązanie problemów: Raport nie tylko informuje, które strony zostały zaindeksowane, ale również identyfikuje problemy, które mogą blokować indeksację innych stron. Może to obejmować błędy serwera, problemy z zablokowanymi zasobami, błędy w plikach robots.txt, czy problemy z przekierowaniami.
Dlaczego Google Search Console jest tak ważne? GSC jest bezpośrednim mostem między Twoją stroną a Google. Daje Ci wgląd w to, jak wyszukiwarka widzi Twoją witrynę, i pozwala na szybkie reagowanie na wszelkie problemy związane z indeksacją. Regularne monitorowanie stanu indeksu za pomocą Google Search Console jest kluczowe dla utrzymania i poprawy widoczności Twojej strony w wynikach wyszukiwania.
W następnych sekcjach omówimy kolejne metody i narzędzia, które mogą wspomóc poprawę indeksacji i widoczności Twojej strony w sieci.
Google Search Console → zakładka Sprawdzanie adresu URL
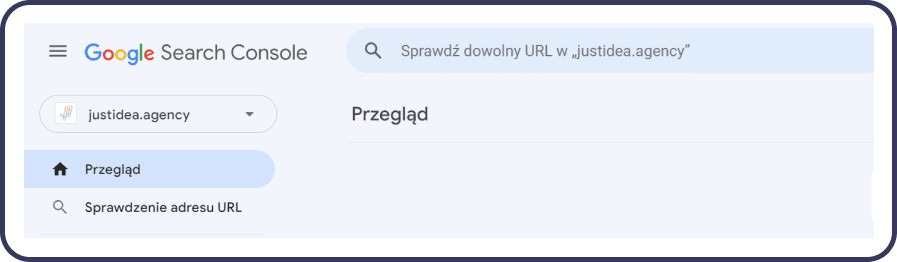
Narzędzie „Sprawdzanie adresu URL” dostępne w Google Search Console to potężne narzędzie, które pozwala właścicielom stron internetowych na dokładne zbadanie, jak Google widzi poszczególne strony ich witryn. Dzięki temu narzędziu możesz sprawdzić, czy konkretne strony są zaindeksowane, oraz uzyskać szczegółowe informacje na temat ewentualnych problemów, które mogą wpływać na indeksację i widoczność w wyszukiwarce. Oto jak możesz wykorzystać tę funkcję do poprawy widoczności Twojej strony:
Jak używać zakładki „Sprawdzanie adresu URL”?

- Wybierz stronę do analizy: Po zalogowaniu się do Google Search Console, skorzystaj z pola „Sprawdź dowolny adres URL w Twojej domenie” znajdującego się na górze strony głównej. Wpisz adres URL strony, którą chcesz sprawdzić, i naciśnij Enter.
- Analiza wyników: Narzędzie przeprowadzi analizę i przedstawi szczegółowe informacje na temat statusu indeksacji danej strony. Zostaniesz poinformowany, czy strona jest zaindeksowana, czy są jakieś problemy z indeksacją, a także otrzymasz dane dotyczące ostatniej pomyślnej indeksacji.
- Zidentyfikuj i rozwiąż problemy: Jeśli narzędzie wykryje problemy, takie jak błędy w indeksacji, ostrzeżenia dotyczące zablokowanych zasobów czy problemy z przekierowaniami, zostaną one szczegółowo opisane wraz z zaleceniami, jak je naprawić. Możesz wtedy podjąć odpowiednie działania, aby usunąć te problemy i poprawić widoczność swojej strony.
- Żądanie zaindeksowania: Jeśli wprowadziłeś zmiany na stronie lub po raz pierwszy sprawdzasz jej status, możesz użyć opcji „Żądanie indeksacji”. Jest to sygnał dla Google, aby ponownie przeskanowało daną stronę, co może przyspieszyć aktualizację jej statusu w indeksie.
Screaming Frog a analiza indeksacji strony
Screaming Frog jest kluczowym narzędziem w arsenale specjalistów SEO, umożliwiającym głęboką analizę i diagnostykę problemów technicznych strony, które mogą wpływać na jej indeksację przez Google. Wykorzystanie Screaming Frog do analizy indeksacji strony pozwala na szczegółowe zrozumienie, jak wyszukiwarki widzą Twoją stronę, i identyfikację potencjalnych przeszkód, które mogą utrudniać jej prawidłowe zaindeksowanie i ranking.
Jak Screaming Frog pomaga w analizie indeksacji strony internetowej?
- Odkrywanie stron niezaindeksowanych: Screaming Frog może szybko zidentyfikować strony, które nie są zaindeksowane przez wyszukiwarki, poprzez sprawdzenie statusów odpowiedzi HTTP oraz tagów meta robots. Umożliwia to natychmiastowe rozpoznanie i naprawienie problemów z dostępnością treści dla robotów wyszukiwarek.
- Analiza dyrektyw robots.txt i tagów meta robots: Narzędzie pozwala na sprawdzenie, czy na stronie nie ma błędnie ustawionych dyrektyw, które mogą blokować indeksację. Poprzez analizę pliku robots.txt oraz tagów meta robots, Screaming Frog umożliwia identyfikację i korektę błędów konfiguracyjnych.
- Wykrywanie zduplikowanych treści: Dzięki Screaming Frog możesz łatwo znaleźć zduplikowane tytuły stron, opisy meta oraz treści, które mogą negatywnie wpływać na indeksację i ranking Twojej strony. Narzędzie pozwala na szybkie zlokalizowanie i usunięcie duplikatów, co jest kluczowe dla optymalizacji SEO.
- Sprawdzanie ścieżek przekierowań: Screaming Frog umożliwia identyfikację i naprawę skomplikowanych lub uszkodzonych przekierowań 301/302, które mogą wpływać na proces indeksacji. Poprzez analizę łańcucha przekierowań, można zoptymalizować ścieżki dostępu do treści i ułatwić robotom wyszukiwarek prawidłowe zaindeksowanie strony.
- Optymalizacja linkowania wewnętrznego: Narzędzie oferuje kompleksowe spojrzenie na strukturę linkowania wewnętrznego strony, co jest kluczowe dla indeksacji i dystrybucji wartości linkowej (PageRank) w obrębie witryny. Screaming Frog pozwala na identyfikację słabych punktów w sieci linków wewnętrznych i ich optymalizację.
Screaming Frog dostarcza cennych wskazówek i narzędzi do diagnozowania oraz naprawiania problemów, które mogą utrudniać indeksację i negatywnie wpływać na widoczność strony w wynikach wyszukiwania. Regularne korzystanie z Screaming Frog do analizy indeksacji pomaga w utrzymaniu zdrowej, łatwo dostępnej dla wyszukiwarek struktury witryny, co jest kluczowe dla osiągnięcia i utrzymania wysokich pozycji w rankingu.
Zastosowanie noindex jako problem z indeksowaniem witryny
Noindex jest często stosowany narzędziem w zarządzaniu treścią na stronach internetowych, ale jego nieprawidłowe użycie może prowadzić do poważnych problemów z indeksowaniem witryny w wyszukiwarkach takich jak Google. Ten tag instruuje roboty wyszukiwarek, aby nie indeksowały danej strony, co oznacza, że strona ta nie pojawi się w wynikach wyszukiwania. Chociaż może to być przydatne w pewnych sytuacjach, nieodpowiednie zastosowanie tego tagu może niechcący ukryć ważne treści przed oczami potencjalnych odwiedzających.
Dlaczego zastosowanie noindex może być problemem?
- Nieintencjonalne wykluczenie ważnych stron: Jeśli metatag noindex zostanie przypadkowo dodany do ważnych stron, które powinny być widoczne w wyszukiwarce, może to znacząco zaszkodzić widoczności Twojej strony w internecie i ograniczyć ruch organiczny.
- Zmniejszenie ruchu organicznego: Strony oznaczone jako noindex są pomijane przez wyszukiwarki, co oznacza, że wszelkie informacje lub wartości, które mogłyby przyciągnąć użytkowników, nie będą dostępne w wynikach wyszukiwania.
- Wpływ na linkowanie wewnętrzne: Strony oznaczone jako noindex mogą również wpływać na ogólną strukturę linkowania wewnętrznego i hierarchię witryny, co może negatywnie wpłynąć na SEO innych stron.
Jak zidentyfikować i naprawić niechciane użycie noindex?
- Przejrzyj swoje strony: Regularnie przeglądaj strony swojej witryny w poszukiwaniu niezamierzonego użycia metatagu noindex. Możesz to zrobić ręcznie lub za pomocą narzędzi SEO, które potrafią zeskanować Twoją witrynę i zidentyfikować użycie tego tagu.
- Wykorzystaj Google Search Console: Narzędzie to pozwala zidentyfikować strony, które są zablokowane przed indeksacją. Możesz użyć funkcji „Sprawdzanie adresu URL” w Google Search Console, aby sprawdzić, czy na danej stronie jest zastosowany metatag noindex.
- Usuń lub zmodyfikuj tag noindex: Jeśli zidentyfikujesz strony, na których niechcący zastosowano noindex, należy usunąć ten tag lub zmienić jego użycie, aby umożliwić indeksowanie strony.
- Zaktualizuj mapę witryny: Po usunięciu tagów noindex z ważnych stron, upewnij się, że są one zawarte w zaktualizowanej mapie witryny, a następnie prześlij mapę do Google Search Console, aby przyspieszyć proces ponownej indeksacji.
Zrozumienie i właściwe zarządzanie metatagiem noindex jest kluczowe dla utrzymania dobrej widoczności witryny w wyszukiwarkach. Regularne audyty SEO i świadome zarządzanie tagami meta to fundamenty skutecznej strategii SEO, która pozwala uniknąć niepotrzebnych problemów z indeksacją.
Ustawienia w pliku Robots.txt a problemy z indeksowaniem
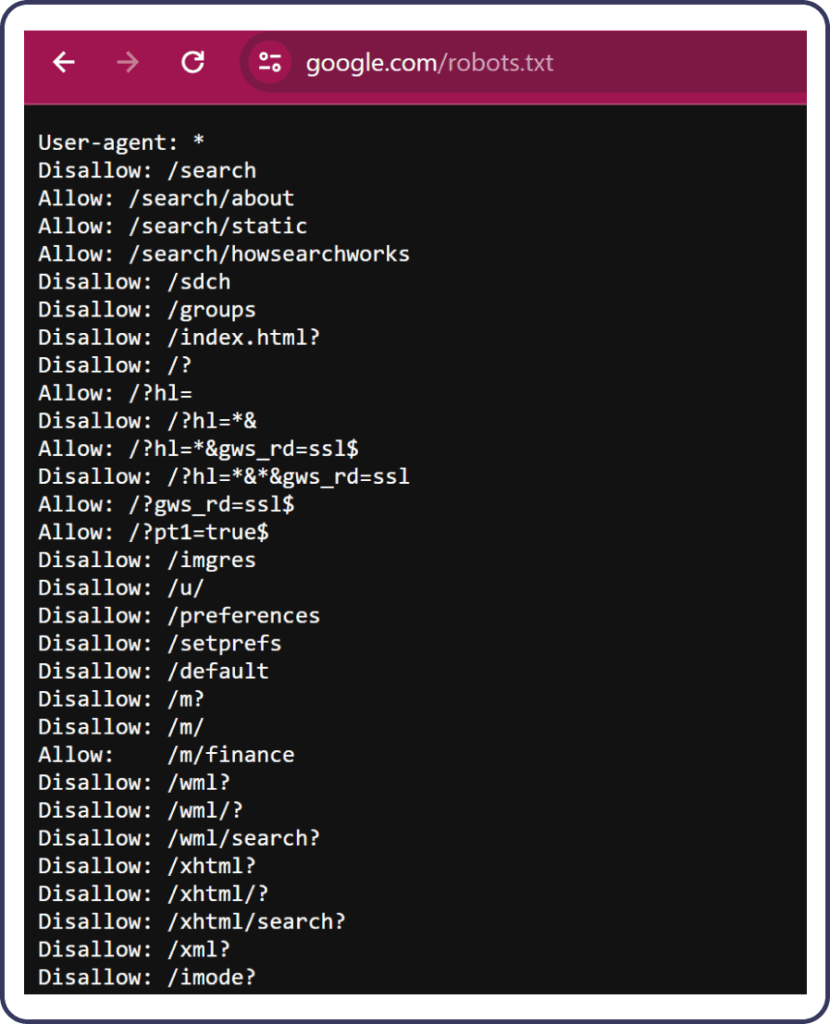
Plik robots.txt pełni kluczową rolę w komunikacji witryny z robotami wyszukiwarek. Jest to pierwsze miejsce, do którego roboty kierują się, gdy odwiedzają witrynę, aby zrozumieć, które części witryny mogą być przeszukiwane i indeksowane. Nieprawidłowe konfiguracje w tym pliku mogą prowadzić do problemów z indeksowaniem, ograniczając widoczność strony w wynikach wyszukiwania. Zrozumienie, jak prawidłowo skonfigurować robots.txt, jest zatem niezbędne dla każdego właściciela strony internetowej, który chce poprawić swoją widoczność online.
Plik robots.txt znajduje się w głównym katalogu witryny i zawiera instrukcje dla robotów wyszukiwarek dotyczące tego, które części witryny mogą być przeszukiwane. Instrukcje te mogą zezwalać lub zabraniać dostępu do określonych katalogów lub plików na serwerze.
Typowe problemy z plikiem Robots.txt:
- Zbyt restrykcyjne ustawienia: Zablokowanie zbyt wielu sekcji witryny może uniemożliwić wyszukiwarkom dostęp do wartościowych treści, co wpłynie na indeksowanie i ranking strony.
- Błędy w składni: Nieprawidłowa składnia w pliku robots.txt może prowadzić do niezamierzonych konsekwencji, takich jak ignorowanie pliku przez roboty lub błędne interpretacje zasad.
- Zablokowanie ważnych zasobów: Blokowanie dostępu do plików JavaScript, CSS lub obrazów może utrudnić robotom zrozumienie i prawidłowe renderowanie strony, co negatywnie wpłynie na SEO.
Jak poprawnie skonfigurować plik Robots.txt?
- Użyj dyrektyw Disallow i Allow z umiarem: Precyzyjnie określ, które sekcje witryny powinny być wykluczone z indeksowania, nie blokując dostępu do kluczowych zasobów.
- Testuj plik przed wdrożeniem: Użyj narzędzia Google Search Console do testowania pliku robots.txt i upewnij się, że nie blokuje on ważnych zasobów.
- Aktualizuj plik zgodnie z potrzebami: Regularnie przeglądaj i aktualizuj plik robots.txt, aby upewnić się, że odpowiada on aktualnym celom SEO i strukturze witryny.
- Zastosuj dyrektywę Sitemap: Dodaj do pliku robots.txt ścieżkę do mapy witryny, aby ułatwić robotom wyszukiwarek znalezienie i indeksowanie stron.
Prawidłowa konfiguracja pliku robots.txt jest niezbędna dla efektywnej komunikacji z robotami wyszukiwarek i może znacząco wpłynąć na sukces SEO witryny. Upewnienie się, że plik jest optymalnie skonfigurowany, zapewnia, że wartościowe treści są dostępne dla wyszukiwarek i mogą być skutecznie indeksowane.
Blokada hasłem jako problem z indeksowaniem
Blokada hasłem strony lub jej części jest częstą praktyką, zwłaszcza gdy chcemy ograniczyć dostęp do określonych treści tylko dla wybranych użytkowników. Jednakże, ta metoda ochrony prywatności i bezpieczeństwa może stanowić znaczącą przeszkodę w procesie indeksowania przez wyszukiwarki. Gdy strona internetowa lub jej sekcja jest chroniona hasłem, roboty wyszukiwarek, takie jak Googlebot, nie są w stanie uzyskać dostępu do tych treści, co skutkuje ich nieobecnością w wynikach wyszukiwania.
Jak blokada hasłem wpływa na indeksowanie?
- Brak dostępu do treści: Gdy robot wyszukiwarki napotyka na stronę chronioną hasłem, nie może ona przeanalizować jej zawartości, co uniemożliwia jej indeksowanie i ranking w wynikach wyszukiwania.
- Ograniczenie widoczności: Strony chronione hasłem są niewidoczne w wyszukiwarkach, co ogranicza zasięg potencjalnej widowni i zmniejsza ruch organiczny kierowany na witrynę.
- Utrata wartości SEO: Ważne treści zablokowane za hasłem mogą zawierać słowa kluczowe i inne elementy wartościowe dla SEO, których wyszukiwarki nie mogą użyć do oceny i klasyfikacji strony.
Błędy w pliku .htaccess jako problem z indeksowaniem
Plik .htaccess jest potężnym narzędziem na serwerach opartych na Apache, które umożliwia zarządzanie konfiguracją serwera na poziomie katalogu. Umożliwia on wykonanie wielu zadań, takich jak przekierowania stron, konfiguracja zabezpieczeń, i manipulacja URL-ami. Niemniej jednak, nieprawidłowa konfiguracja tego pliku może prowadzić do poważnych problemów z indeksowaniem stron w wyszukiwarkach.
Typowe błędy w pliku .htaccess wpływające na indeksowanie:
- Nieprawidłowe przekierowania: Błędnie skonfigurowane przekierowania mogą powodować pętle przekierowań lub błędy 404 (Not Found), co utrudnia robotom wyszukiwarek dostęp do treści.
- Błędne użycie dyrektyw Disallow lub Allow: Niepoprawne użycie tych dyrektyw może blokować dostęp do całej witryny lub jej ważnych części, uniemożliwiając indeksowanie.
- Niepoprawne ustawienia cache: Nieprawidłowo skonfigurowane dyrektywy dotyczące cache mogą wpływać na sposób, w jaki treści są serwowane robotom wyszukiwarek, potencjalnie wprowadzając je w błąd co do aktualności treści.
- Użycie dyrektyw zabezpieczających: Zbyt restrykcyjne zasady bezpieczeństwa mogą nieumyślnie blokować dostęp do strony dla robotów wyszukiwarek.
- Błędy składni: Nawet najmniejsze błędy składniowe w pliku .htaccess mogą spowodować, że cała konfiguracja będzie ignorowana przez serwer, co może mieć nieprzewidziane skutki dla dostępności i indeksowania strony.
Jak unikać błędów w pliku .htaccess?
- Dokładne testowanie: Zanim wprowadzisz zmiany na żywo, dokładnie przetestuj konfigurację w środowisku testowym. To pozwoli na wykrycie i naprawienie potencjalnych problemów bez wpływu na dostępność witryny.
- Używanie narzędzi do walidacji: Istnieją narzędzia online, które mogą pomóc w walidacji składni pliku .htaccess, co jest szczególnie przydatne w wykrywaniu subtelnych błędów.
- Stopniowe wdrażanie zmian: Wprowadzaj zmiany stopniowo, zamiast dokonywać wielu modyfikacji naraz. Pozwala to na łatwiejsze zidentyfikowanie przyczyny potencjalnych problemów.
- Dokumentacja i komentarze: Utrzymuj dokumentację zmian wprowadzonych w pliku .htaccess i używaj komentarzy w pliku, aby wyjaśnić cel poszczególnych dyrektyw. To ułatwi zarządzanie konfiguracją w przyszłości.
- Edukacja i doświadczenie: Zwiększaj swoją wiedzę i doświadczenie w zakresie konfiguracji serwera Apache. Zrozumienie możliwości i ograniczeń pliku .htaccess jest kluczowe dla efektywnego zarządzania witryną.
Poprawna konfiguracja pliku .htaccess jest kluczowa dla zapewnienia, że witryna jest dostępna i może być efektywnie indeksowana przez wyszukiwarki. Unikanie powyższych błędów pomoże w utrzymaniu zdrowia SEO strony i zapewni, że jej treści będą widoczne w wynikach wyszukiwania.
Blokada na poziomie serwera jako problem z indeksowaniem
Blokada na poziomie serwera to jeden z mniej oczywistych, ale równie znaczących problemów, które mogą uniemożliwić indeksowanie strony przez wyszukiwarki. Ta forma blokady może wystąpić z różnych powodów i może być niezamierzonym efektem działań mających na celu zabezpieczenie strony internetowej lub serwera przed atakami, nadmiernym ruchem czy nieautoryzowanym dostępem.
Przyczyny blokady na poziomie serwera:
- Zabezpieczenia przed atakami DDoS: Serwery są często konfigurowane tak, aby ograniczać liczbę żądań od pojedynczego źródła w danym okresie czasu. Roboty wyszukiwarek, szczególnie podczas pełzania przez duże witryny, mogą zostać błędnie zidentyfikowane jako źródło ataku DDoS.
- Geograficzne blokady IP: Niektóre strony stosują blokady geograficzne, aby ograniczyć dostęp do treści dla użytkowników z określonych regionów. Jeśli serwery wyszukiwarek są w tych regionach, może to uniemożliwić indeksowanie.
- Blokady IP ze względów bezpieczeństwa: Serwery mogą być skonfigurowane do blokowania adresów IP, które są uznawane za zagrożenie. Niewłaściwa konfiguracja lub zbyt agresywne zabezpieczenia mogą prowadzić do blokowania robotów wyszukiwarek.
- Nieprawidłowa konfiguracja zapory sieciowej (firewall): Zaporę sieciową można skonfigurować tak, aby blokowała nieznane lub niezaufane żądania do serwera, co może obejmować także ruch od wyszukiwarek.
Jak zarządzać blokadami na poziomie serwera?
- Monitorowanie logów serwera: Regularne przeglądanie logów serwera pozwoli na wczesne wykrycie, czy żądania od robotów wyszukiwarek są blokowane.
- Dokładna konfiguracja zabezpieczeń: Zabezpieczenia należy konfigurować tak, aby rozróżniały między niebezpiecznym ruchem a legalnymi żądaniami od robotów wyszukiwarek.
- Wykorzystanie plików robots.txt: Plik robots.txt pozwala na komunikację z robotami wyszukiwarek i powinien być używany do zarządzania ich dostępem, zamiast stosowania twardych blokad na poziomie serwera.
- Zezwolenie na żądania od znanych robotów wyszukiwarek: Można skonfigurować zaporę sieciową i inne mechanizmy bezpieczeństwa, aby explicite zezwalały na ruch od znanych i zaufanych robotów wyszukiwarek.
- Konsultacja z dostawcą hostingu: W niektórych przypadkach warto skonsultować się z dostawcą usług hostingowych, aby upewnić się, że konfiguracja serwera nie wpływa negatywnie na indeksowanie strony przez wyszukiwarki.
Zarządzanie blokadami na poziomie serwera wymaga równowagi między zapewnieniem bezpieczeństwa a umożliwieniem wyszukiwarkom dostępu do treści strony. Przemyślana konfiguracja i ciągła weryfikacja ustawień to klucz do sukcesu w zapewnieniu, że strona będzie widoczna i indeksowana przez wyszukiwarki.
Błędny kod odpowiedzi HTTP jako problem z indeksowaniem
Kody odpowiedzi HTTP stanowią ważny element komunikacji między serwerem a klientem (np. przeglądarką internetową lub robotem wyszukiwarki), informując o stanie żądania. Błędne kody odpowiedzi HTTP mogą znacząco wpłynąć na zdolność strony do bycia indeksowaną przez Google i inne wyszukiwarki. Poniżej przedstawiamy, jak błędne kody odpowiedzi mogą wpływać na indeksowanie i jak zarządzać potencjalnymi problemami.
Najczęstsze błędne kody odpowiedzi i ich wpływ:
- 404 Not Found: Oznacza, że strona nie została znaleziona. Jeśli strona generuje dużą liczbę błędów 404, może to wpłynąć na ocenę jakości witryny przez wyszukiwarki.
- 500 Internal Server Error: Wskazuje na problem z serwerem, który uniemożliwia zwrócenie jakiejkolwiek konkretnej treści. Częste błędy 500 mogą zniechęcać roboty wyszukiwarek do dalszego indeksowania strony.
- 302 Found / 307 Temporary Redirect: Chociaż przekierowania te nie są błędne same w sobie, nadmierne lub nieprawidłowe ich używanie (np. zamiast stałych przekierowań 301) może wprowadzać w błąd roboty wyszukiwarek co do stałości zawartości.
- 503 Service Unavailable: Ten kod jest używany, gdy serwer jest tymczasowo niedostępny, na przykład podczas konserwacji. Jeśli jest używany przez długi czas lub zbyt często, może to wpłynąć na indeksowanie.
Jak zarządzać błędnymi kodami odpowiedzi HTTP:
- Monitorowanie logów serwera i raportów w Google Search Console: Regularne sprawdzanie logów serwera i korzystanie z Google Search Console pozwoli na szybkie wykrywanie błędów odpowiedzi HTTP.
- Optymalizacja konfiguracji serwera: Zapewnienie, że serwer jest odpowiednio skonfigurowany do obsługi żądań, może zmniejszyć ryzyko wystąpienia błędów 500 i innych problemów.
- Wykorzystanie przekierowań 301 zamiast 302/307: Stałe przekierowania (301) powinny być używane do przeniesienia treści na nowe URL-e, zapewniając, że wartość SEO jest przekazywana do nowego adresu.
- Odpowiednie zarządzanie stronami z błędem 404: Tworzenie przyjaznych użytkownikowi stron błędu 404 z linkami do głównej strony lub mapy witryny może poprawić doświadczenie użytkownika i ułatwić robotom wyszukiwarek nawigację.
Zarządzanie błędnymi kodami odpowiedzi HTTP wymaga ciągłej uwagi i proaktywnego podejścia, aby zapewnić, że nie wpłyną one negatywnie na widoczność strony w wyszukiwarkach.
Nałożenie kary od Google jako problem z indeksowaniem
Google stawia sobie za cel dostarczanie użytkownikom najbardziej wartościowych i trafnych wyników wyszukiwania. W tym celu stosuje szereg wytycznych, których przestrzeganie jest kluczowe dla właścicieli stron internetowych. Naruszenie tych wytycznych może skutkować nałożeniem kary na stronę, co bezpośrednio wpływa na jej widoczność i indeksowanie. W tym segmencie wyjaśniamy, czym jest kara od Google, jakie są jej rodzaje i jak zarządzać potencjalnymi problemami związanymi z karami.
Rodzaje kar od Google:
- Kary manualne: Są to kary nakładane przez zespół Google po przeglądzie strony, który ujawnił praktyki naruszające wytyczne Google dla webmasterów. Informacja o takiej karze jest dostępna w Google Search Console.
- Kary algorytmiczne: Są to kary nakładane automatycznie przez algorytmy Google, które wykrywają manipulowanie wynikami wyszukiwania (np. przez nieprawidłowe optymalizacje SEO, nienaturalny profil linków zewnętrznych).
Jak zarządzać nałożeniem kary od Google:
- Analiza i identyfikacja problemu: Pierwszym krokiem jest zrozumienie, dlaczego kara została nałożona. Google Search Console często dostarcza informacji o manualnych karach, wskazując konkretne problemy do rozwiązania.
- Korygowanie problemów: Po zidentyfikowaniu problemu należy podjąć działania naprawcze, takie jak usunięcie niskiej jakości treści, poprawienie problemów z linkami przychodzącymi lub usuwanie ukrytego tekstu i nadmiernej optymalizacji.
- Wniosek o ponowne rozpatrzenie: W przypadku kar manualnych, po rozwiązaniu problemów należy złożyć wniosek o ponowne rozpatrzenie do Google przez Google Search Console. Wniosek powinien zawierać szczegółowy opis podjętych działań naprawczych.
- Monitorowanie i prewencja: Po rozwiązaniu problemu ważne jest monitorowanie strony pod kątem przestrzegania wytycznych Google oraz wdrażanie strategii prewencyjnych, aby uniknąć przyszłych kar.
Nałożenie kary od Google może znacznie wpłynąć na widoczność strony w wynikach wyszukiwania. Kluczem do zarządzania taką sytuacją jest szybka identyfikacja i korygowanie naruszeń wytycznych Google, a następnie skuteczne komunikowanie się z Google poprzez wniosek o ponowne rozpatrzenie.
Atak hakerski jako problem z indeksowaniem strony
Ataki hakerskie na strony internetowe mogą mieć poważne konsekwencje dla widoczności i indeksowania witryny w wyszukiwarkach. Hakerzy mogą „wstrzyknąć” złośliwe oprogramowanie, zmienić treść strony, dodać niechciane linki lub nawet przekierować użytkowników do innych witryn. Wszystkie te działania mogą negatywnie wpłynąć na ranking strony w wynikach wyszukiwania Google oraz zaszkodzić jej reputacji. W tym segmencie omówimy, jak atak hakerski wpływa na indeksowanie i co można zrobić, aby zminimalizować szkody.
Skutki ataku hakerskiego na indeksowanie:
- Zmiana treści: Nieautoryzowane zmiany treści mogą spowodować, że strona będzie indeksowana z nieodpowiednimi słowami kluczowymi, co wpłynie na jej widoczność.
- Wstrzyknięcie złośliwego oprogramowania: Google aktywnie identyfikuje strony, które mogą stanowić zagrożenie dla użytkowników, i może je usunąć z wyników wyszukiwania lub oznaczyć jako niebezpieczne.
- Spadek zaufania: Ataki mogą spowodować spadek zaufania użytkowników oraz wyszukiwarek do witryny, co wpływa na jej ranking i widoczność.
Jak zarządzać skutkami ataku hakerskiego:
- Szybka identyfikacja i reakcja: Kluczowym elementem jest szybka identyfikacja ataku i podjęcie działań w celu zabezpieczenia strony. Może to obejmować zmianę haseł, aktualizację oprogramowania i usunięcie złośliwego kodu.
- Korzystanie z Google Search Console: Google Search Console (GSC) jest nieocenionym narzędziem w identyfikowaniu problemów związanych z bezpieczeństwem. Google może powiadomić właścicieli witryn o potencjalnych problemach z bezpieczeństwem przez GSC.
- Czyszczenie i przywracanie witryny: Po zabezpieczeniu strony, ważne jest dokładne usunięcie wszystkich śladów ataku, w tym złośliwego oprogramowania i nieautoryzowanych zmian treści.
- Wniosek o ponowne skanowanie witryny przez Google: Po usunięciu szkód warto poprosić Google o ponowne zeskanowanie strony, aby upewnić się, że wszystkie złośliwe oprogramowanie zostało usunięte i że strona jest bezpieczna dla użytkowników.
- Wdrożenie środków zapobiegawczych: Aby uniknąć przyszłych ataków, ważne jest wdrożenie solidnych środków bezpieczeństwa, takich jak regularne aktualizacje oprogramowania, stosowanie silnych haseł, korzystanie z zabezpieczeń typu firewall i monitorowanie strony pod kątem nieautoryzowanych zmian.
Atak hakerski może mieć poważne konsekwencje dla indeksowania i widoczności strony w wyszukiwarkach. Szybka identyfikacja, skuteczne zarządzanie kryzysowe oraz wdrożenie solidnych środków bezpieczeństwa są kluczowe do minimalizowania szkód i ochrony przed przyszłymi atakami. Regularne monitorowanie i utrzymanie aktualności oprogramowania są niezbędne dla zapewnienia bezpieczeństwa witryny w długim okresie.
Problemy związane z treścią na stronie – duplicate content, thin content
Jednymi z głównych wyzwań w optymalizacji strony pod kątem wyszukiwarek (SEO) są problemy związane z treścią, takie jak duplicate content (zduplikowana treść) i thin content (płytka treść). Oba te problemy mogą znacząco wpłynąć na zdolność strony do osiągania wysokich pozycji w wynikach wyszukiwania i mogą być przyczyną problemów z indeksowaniem. W tym segmencie omówimy, czym są te problemy i jak można je rozwiązać, aby poprawić widoczność strony.
Duplicate Content (Zduplikowana treść)
Zduplikowana treść występuje, gdy identyczne lub bardzo podobne treści pojawiają się na różnych stronach w obrębie tej samej witryny lub na różnych witrynach internetowych. Google i inne wyszukiwarki preferują unikalne treści, ponieważ chcą dostarczać użytkownikom najbardziej wartościowe i różnorodne informacje.
Jakie są problemy ze zduplikowaną treścią:
- Kanibalizacja słów kluczowych: Podobne strony mogą konkurować ze sobą o te same słowa kluczowe, co obniża ich potencjalną pozycję w wynikach wyszukiwania.
Jak rozwiązać problemy z duplicate content:
- Użycie tagu canonical: Wskazuje wyszukiwarkom preferowaną wersję zduplikowanej treści do indeksowania.
- Przekierowania 301: Przekierowania stałe mogą być używane do kierowania ruchu i wartości linków do preferowanej wersji treści.
- Usprawnienie zarządzania treścią: Zapewnienie, że każda strona na witrynie zawiera unikalną i wartościową treść.
Thin Content (Płytka treść)
Płytka treść to strony o niewielkiej lub żadnej wartości dla użytkownika, często charakteryzujące się niską liczbą słów, brakiem unikalnych informacji lub brakiem związku z tematem strony.
Jakie są problemy z thin content:
- Niska wartość dla użytkowników: Strony z płytka treścią rzadko zapewniają odpowiedzi na pytania użytkowników, co może prowadzić do wysokiego wskaźnika odrzuceń (Bounce Rate) i niskiego czasu spędzonego na stronie.
- Niska pozycja w wynikach wyszukiwania: Google promuje strony oferujące bogate i wartościowe treści, co oznacza, że strony z płytka treścią często zajmują niskie pozycje w wynikach wyszukiwania.
Jak rozwiązać problemy z płytką treścią:
- Zwiększenie wartości treści: Inwestowanie w bogate, wartościowe i unikalne treści, które odpowiadają na potrzeby i pytania użytkowników.
- Struktura i formatowanie: Ulepszenie czytelności treści przez stosowanie nagłówków, list punktowych i grafik, aby strony były bardziej angażujące i wartościowe dla czytelników.
- Analiza i optymalizacja słów kluczowych: Zapewnienie, że treści na stronie odpowiadają zainteresowaniom i zapytaniom użytkowników wyszukiwarki.
Zarządzanie treścią na stronie wymaga ciągłej uwagi i optymalizacji. Zrozumienie i rozwiązanie problemów związanych z zduplikowaną i płytka treścią jest kluczowe dla poprawy pozycji strony w wynikach wyszukiwania i zapewnienia lepszego doświadczenia dla użytkowników. Wdrożenie najlepszych praktyk SEO i tworzenie wartościowych, unikalnych treści przyczynia się do sukcesu długoterminowego w internecie.
Jesteś zainteresowany poprawą indeksowania strony oraz jej widoczności?


Canonical – niewłaściwa implementacja lub jej brak jako problem w indeksacji
Tagi canonical odgrywają kluczową rolę w optymalizacji strony internetowej dla wyszukiwarek (SEO), pomagając określić, która wersja strony powinna być traktowana jako główna w przypadku, gdy dostępne są duplikaty lub bardzo podobne treści. Niewłaściwa implementacja lub całkowity brak tych tagów może prowadzić do problemów z indeksacją i, co za tym idzie, z widocznością strony w wynikach wyszukiwania.
Dlaczego to ważne?
- Unikanie duplikacji treści: Wyszukiwarki dążą do zapewnienia unikalnych i wartościowych wyników wyszukiwania. Jeśli różne wersje tej samej treści są dostępne pod różnymi adresami URL bez wyraźnego wskazania, która wersja jest preferowana, może to prowadzić do rozproszenia wartości SEO między duplikatami.
- Skoncentrowanie wartości linków (link juice): Poprzez wskazanie preferowanego URL za pomocą tagu canonical, można skoncentrować wartość SEO na jednej, wybranej stronie, nawet jeśli inne strony linkują do różnych wersji duplikatu.
- Optymalizacja indeksacji: Tag canonical pomaga wyszukiwarkom zrozumieć, którą wersję strony należy indeksować, co zapobiega marnowaniu zasobów na indeksowanie wielu podobnych stron.
Problemy wynikające z niewłaściwej implementacji lub braku tagu canonical
- Rozproszenie wartości SEO: Bez jasnego wskazania, która strona jest „kanoniczna”, linki do i z różnych wersji strony mogą rozproszyć wartość SEO zamiast skupić ją na jednej, optymalnej wersji.
- Problemy z rankingiem: Strony mogą konkurować ze sobą o te same słowa kluczowe, co może prowadzić do gorszego rankingu, niż gdyby wartość była skoncentrowana na jednej stronie.
- Nieefektywne wykorzystanie budżetu na indeksację: Wyszukiwarki mają ograniczone zasoby do indeksowania stron. Indeksowanie wielu wersji tej samej treści może prowadzić do nieefektywnego wykorzystania tych zasobów.
Jak zarządzać tagami canonical w prawidłowy sposób?
- Dokładne wskazanie preferowanej wersji: Upewnij się, że tagi canonical wskazują na preferowany URL, nawet jeśli treść jest dostępna pod różnymi adresami.
- Konsystencja w całej witrynie: Używaj tagów canonical konsekwentnie w całej witrynie, aby uniknąć mylących sygnałów dla wyszukiwarek.
- Monitorowanie i aktualizacja: Regularnie sprawdzaj konfigurację tagów canonical, zwłaszcza po zmianach na stronie lub jej strukturze, aby upewnić się, że są one nadal poprawnie ustawione.
Prawidłowe zastosowanie tagów canonical jest kluczowe dla efektywnej strategii SEO. Pomaga to w uniknięciu problemów z indeksacją i poprawia ogólną widoczność strony w wynikach wyszukiwania, koncentrując wartość SEO na najbardziej istotnych i wartościowych treściach.
Blokowanie kluczowych skryptów JS, CSS oraz elementów graficznych jako problem w indeksowaniu
W nowoczesnym rozwoju stron internetowych, skrypty JavaScript (JS), arkusze stylów CSS oraz elementy graficzne odgrywają zasadniczą rolę w tworzeniu interaktywnych i wizualnie atrakcyjnych witryn. Jednakże, blokowanie tych kluczowych zasobów może poważnie utrudnić wyszukiwarkom indeksowanie treści strony, co negatywnie wpływa na jej pozycjonowanie w wynikach wyszukiwania. Przeanalizujemy, jak blokowanie tych zasobów wpływa na proces indeksowania i jak można temu zaradzić.
- Utrudnione renderowanie strony: Wyszukiwarki, takie jak Google, używają robotów, które „przechodzą” przez strony internetowe, próbując je renderować w podobny sposób, jak robią to przeglądarki użytkowników. Blokowanie JS, CSS lub elementów graficznych może uniemożliwić robotom wyszukiwarek prawidłowe renderowanie strony, co skutkuje niedokładnym lub niekompletnym indeksowaniem jej treści.
- Zakłócenie analizy treści: Skrypty JavaScript często są wykorzystywane do dynamicznego generowania treści na stronie. Jeżeli te skrypty są zablokowane, wyszukiwarki mogą nie być w stanie uzyskać dostępu do całej treści strony, co wpływa na jej indeksowanie i zrozumienie przez algorytmy wyszukiwania.
- Wpływ na ocenę jakości strony: Arkusze stylów CSS są kluczowe dla wizualnego aspektu strony, a elementy graficzne mogą wzbogacać treść i poprawiać doświadczenie użytkownika. Blokowanie tych zasobów może prowadzić do nieprawidłowego oceniania jakości strony przez wyszukiwarki, ponieważ nie będą one w stanie prawidłowo ocenić jej wyglądu i użyteczności.
Jak zaradzić problemowi z blokowaniem kluczowych skryptów JS, CSS?
- Przegląd pliku robots.txt: Upewnij się, że plik robots.txt nie blokuje dostępu do kluczowych zasobów JS, CSS oraz obrazów. Wykorzystaj Google Search Console, aby zidentyfikować i usunąć wszelkie nieintencjonalne blokady.
- Optymalizacja ładowania zasobów: Zastosuj techniki takie jak leniwe ładowanie (lazy loading) dla obrazów i upewnij się, że kluczowe skrypty i arkusze stylów są ładowane w sposób nieblokujący renderowanie strony.
- Wykorzystanie atrybutów async i defer w tagach skryptów: Pozwala to na asynchroniczne ładowanie lub opóźnione ładowanie skryptów JavaScript, co może poprawić szybkość ładowania strony bez zakłócania procesu indeksowania.
- Testowanie i weryfikacja z pomocą narzędzi do testowania: Użyj narzędzi takich jak Google PageSpeed Insights, Lighthouse oraz funkcji „Fetch as Google” w Google Search Console, aby przetestować, jak wyszukiwarki renderują Twoją stronę i upewnij się, że kluczowe zasoby są dostępne.
Poprawne zarządzanie zasobami strony i zapewnienie, że wyszukiwarki mają do nich dostęp, jest niezbędne dla skutecznego indeksowania i osiągnięcia lepszych wyników w wyszukiwarkach. Eliminowanie blokad na kluczowe skrypty JS, CSS i elementy graficzne pomaga w zapewnieniu, że treść Twojej strony jest poprawnie indeksowana i oceniana przez algorytmy wyszukiwania.
Przekierowania 301 jako problem w indeksacji
Przekierowania 301, znane również jako stałe przekierowania, są standardową metodą informowania przeglądarek internetowych i robotów wyszukiwarek, że dana strona lub zasób został trwale przeniesiony na nowy adres URL. Chociaż przekierowania 301 są użytecznym narzędziem w zarządzaniu treścią i strukturą witryny, ich niewłaściwe lub nadmierne użycie może prowadzić do problemów z indeksacją i, w konsekwencji, z widocznością strony w wynikach wyszukiwania.
Problemy wynikające z niewłaściwego użycia przekierowań 301:
- Łańcuchy przekierowań: Długie łańcuchy przekierowań (przekierowanie prowadzące do kolejnego przekierowania, i tak dalej) mogą spowolnić czas ładowania strony i utrudnić robotom wyszukiwarek dostęp do ostatecznej treści. Może to opóźnić lub zakłócić indeksację strony.
- Rozproszenie wartości SEO: Każde przekierowanie może teoretycznie spowodować niewielką utratę link juice, co oznacza, że strona docelowa może nie otrzymać całkowitej wartości SEO przekazywanej przez linki zewnętrzne wskazujące na oryginalny adres URL.
- Nieaktualne linki i zakładki: Użytkownicy oraz inne strony mogą mieć zapisane stare adresy URL, które zostały przeniesione. Jeśli przekierowania nie są prawidłowo zarządzane, może to prowadzić do frustracji użytkowników i utraty ruchu.
- Problem z duplikacją treści: Jeśli przekierowania 301 nie są konsekwentnie stosowane (np. gdy stare i nowe URL-e są nadal dostępne i indeksowane), może to prowadzić do problemów z duplikacją treści w oczach wyszukiwarek.
Jak zarządzać przekierowaniami 301, aby uniknąć problemów z indeksacją:
- Planuj przekierowania strategicznie: Używaj przekierowań 301 tylko wtedy, gdy jest to absolutnie konieczne, na przykład przy zmianie adresu strony lub reorganizacji struktury witryny.
- Unikaj łańcuchów przekierowań: Staraj się, aby każde przekierowanie prowadziło bezpośrednio do ostatecznego adresu URL, bez pośrednich przekierowań.
- Aktualizuj linki wewnętrzne: Po ustawieniu przekierowań 301, zaktualizuj wszelkie linki wewnętrzne w witrynie, aby bezpośrednio wskazywały na nowe adresy URL, co zmniejszy zależność od przekierowań.
- Monitoruj wydajność witryny: Regularnie sprawdzaj stan witryny za pomocą narzędzi takich jak Google Search Console, aby zidentyfikować i naprawić złamane linki lub problemy z przekierowaniami..
Przekierowania 301 są potężnym narzędziem w zarządzaniu stroną internetową, ale wymagają starannego i strategicznego podejścia, aby nie wpłynęły negatywnie na indeksację i ranking strony. Poprzez właściwe zarządzanie i optymalizację przekierowań, można zapewnić płynne przejście dla użytkowników i wyszukiwarek, minimalizując potencjalne problemy z SEO.
Błędy w pliku sitemap.xml jako problem w indeksacji
Plik sitemap.xml jest jednym z kluczowych elementów technicznego SEO, służącym jako mapa strony dla robotów wyszukiwarek. Ułatwia on indeksację strony przez wyszukiwarki, zapewniając im pełny i aktualny spis URL-i dostępnych na witrynie. Jednak błędy w pliku sitemap.xml mogą poważnie zakłócić proces indeksacji, co może prowadzić do pominięcia istotnych stron przez wyszukiwarki lub indeksowania nieaktualnych lub błędnych URL-i. Poniżej omówimy najczęstsze problemy związane z plikami sitemap.xml i sposoby ich rozwiązania.
Najczęstsze błędy w pliku sitemap.xml
- Nieaktualne URL-e: Włączenie do pliku sitemap.xml URL-i, które nie istnieją lub zostały przeniesione, bez odpowiednich przekierowań 301, może wprowadzić w błąd roboty wyszukiwarek.
- Zduplikowane URL-e: Włączenie zduplikowanych URL-i do mapy strony może prowadzić do nieefektywnego wykorzystania budżetu na indeksację
- Włączenie URL-i zablokowanych przez robots.txt: Dodanie do sitemap.xml URL-i, które zostały zablokowane dla robotów wyszukiwarek w pliku robots.txt, może powodować konflikty i utrudniać indeksację.
- Zbyt duża liczba URL-i: Chociaż pliki sitemap.xml mogą zawierać do 50 000 URL-i, nadmierna liczba linków w jednym pliku może być problematyczna, szczególnie jeśli wiele z nich to niskiej jakości lub mało istotne strony.
- Błędy formatowania: Niewłaściwa struktura pliku sitemap.xml, na przykład błędy w składni XML, może uniemożliwić robotom wyszukiwarek poprawne przetworzenie pliku.
Jak zarządzać plikiem sitemap.xml?
- Regularna aktualizacja: Upewnij się, że plik sitemap.xml jest regularnie aktualizowany, aby odzwierciedlał najnowsze zmiany na stronie, w tym dodanie nowych treści i usunięcie nieaktualnych URL-i.
- Unikaj zduplikowanych URL-i: Sprawdź, czy wszystkie URL-e w pliku sitemap.xml są unikalne i nie zawierają niepotrzebnych parametrów URL, które mogą prowadzić do traktowania ich jako zduplikowane strony.
- Sprawdź zgodność z robots.txt: Przed dodaniem URL-i do pliku sitemap.xml, upewnij się, że nie są one zablokowane w pliku robots.txt.
- Podziel i zreorganizuj mapę strony: Dla dużych witryn rozważ podział mapy strony na mniejsze pliki sitemap.xml, zgrupowanie tematyczne lub według typu treści, co ułatwi zarządzanie i przeglądanie przez roboty wyszukiwarek.
- Walidacja pliku: Regularnie korzystaj z narzędzi do walidacji XML, aby upewnić się, że plik sitemap.xml nie zawiera błędów składniowych i jest poprawnie sformatowany.
- Wykorzystanie Google Search Console: Użyj Google Search Console do przesłania pliku sitemap.xml i monitorowania raportów dotyczących indeksowania, co pozwoli na szybkie wykrycie i naprawienie ewentualnych błędów.
Poprawnie zarządzany plik sitemap.xml jest niezbędny dla efektywnego indeksowania i optymalizacji strony pod kątem wyszukiwarek. Regularne przeglądanie i aktualizowanie mapy strony może znacząco poprawić zdolność witryny do szybkiego i dokładnego indeksowania przez wyszukiwarki, co przekłada się na lepszą widoczność w wynikach wyszukiwania.
Jak zgłosić stronę do indeksacji?
Zgłaszanie strony do indeksacji jest ważnym krokiem w procesie optymalizacji strony pod kątem wyszukiwarek (SEO). Pozwala to upewnić się, że nowe lub zaktualizowane treści są szybko rozpoznawane i indeksowane przez wyszukiwarki, takie jak Google. Oto, jak możesz zgłosić swoją stronę do indeksacji:
1. Użyj Google Search Console
Google Search Console (GSC) jest najbardziej bezpośrednim sposobem na zgłoszenie strony do Google. Jeśli jeszcze tego nie zrobiłeś, musisz najpierw zweryfikować swoją własność w GSC. Po zweryfikowaniu postępuj zgodnie z poniższymi krokami:
- Zaloguj się do Google Search Console i wybierz właściwą własność (stronę).
- Przejdź do zakładki „Sprawdzenie adresu URL” i wprowadź pełny adres URL strony, którą chcesz zgłosić do indeksacji, w pole wyszukiwania na górze strony.
- Naciśnij Enter, aby Google mogło przetestować URL. Narzędzie sprawdzi, czy strona jest już indeksowana i czy występują jakiekolwiek problemy.
- Jeśli strona nie jest indeksowana, pojawi się opcja „Poproś o zindeksowanie”. Kliknij ten przycisk, aby zgłosić stronę do indeksacji przez Google.
2. Utwórz i zaktualizuj plik sitemap.xml
Sitemap.xml to plik, który zawiera informacje o stronach na Twojej witrynie, które chcesz, aby były indeksowane przez wyszukiwarki. Upewnij się, że plik sitemap jest aktualny i zawiera wszystkie istotne strony, a następnie zgłoś go lub zaktualizuj w Google Search Console:
- W Google Search Console, przejdź do sekcji „Mapy strony”.
- Usuń stare mapy strony, jeśli takie istnieją, a następnie dodaj ścieżkę do nowego pliku sitemap i kliknij „Prześlij”.
3. Utrzymuj linkowanie wewnętrzne i zewnętrzne w dobrej kondycji
Utrzymywanie zdrowego profilu linkowania wewnętrznego i zewnętrznego na Twojej stronie również może pomóc w szybszej indeksacji. Wyszukiwarki używają linków do odkrywania nowych stron, więc upewnij się, że nowe lub zaktualizowane strony są dobrze powiązane z resztą Twojej witryny.
Pamiętaj, że choć zgłoszenie strony do indeksacji może przyspieszyć jej rozpoznanie przez wyszukiwarki, ostateczne decyzje dotyczące indeksowania i rankingu podejmuje algorytm wyszukiwarki na podstawie wielu czynników, w tym jakości i unikalności treści.
Podsumowanie: Jak zapewnić skuteczną indeksację Twojej strony w Google?
Zapewnienie, że Twoja strona internetowa jest poprawnie indeksowana przez Google, jest kluczowym elementem sukcesu witryny w wyszukiwarce Google. Problemy z indeksacją mogą wynikać z różnych przyczyn, w tym z niewłaściwej implementacji tagów canonical, błędów w pliku sitemap.xml, nadużywania przekierowań 301, czy blokowania kluczowych zasobów takich jak JavaScript, CSS i elementy graficzne.
Skontaktuj się z profesjonalistami SEO lub skorzystaj z dostępnych narzędzi, takich jak Google Search Console, aby zdiagnozować i rozwiązać problemy związane z indeksacją. Pamiętaj, że skuteczna indeksacja to podstawa widoczności w internecie i klucz do sukcesu Twojej strony w świecie online.
Nie czekaj, aż Twoja strona zostanie pominięta przez wyszukiwarki. Podjęcie działań już dziś może znacząco wpłynąć na Twoją obecność online i przyciągnąć więcej wartościowego ruchu do Twojej strony.
Sprawdź również:
- Czym jest newsletter i jak go stworzyć?
- Jaką wybrać platformę sklepową?
- Jak sprawdzić swoje opinie w Google?
- Pozycjonowanie WordPress – Poradnik
- Pozycjonowanie sklepu Shoper
- Pozycjonowanie sklepu PrestaShop
- Jak sprawdzić pozycję strony w Google?
- Cookiebot, Consent Mode
- Pozycjonowanie wizytówki Google





















