



AI Answers zmienia SEO — dlaczego dziś nie wystarczy dopasowanie słów kluczowych
Jeszcze kilka lat temu dało się budować widoczność w Google głównie na prostym schemacie: dobierasz frazę, tworzysz stronę „pod słowo kluczowe”, dopinasz meta i linki — i walczysz o pozycję. Ten model nadal działa, ale coraz częściej przestaje być wystarczający. Powód jest prosty: użytkownicy coraz częściej nie szukają już listy wyników, tylko gotowej odpowiedzi. A skoro odpowiedź jest generowana przez system AI, to wygrywają treści, które AI potrafi szybko zrozumieć, porównać i bezpiecznie zacytować.
Od wyników wyszukiwania do „odpowiedzi”
W świecie AI Search logika widoczności zaczyna się przesuwać z „rankingowania stron” na „dobieranie fragmentów informacji”. To właśnie dlatego pojawia się pojęcie AI Answers / answer engines: użytkownik zadaje pytanie, a system nie tylko prezentuje wyniki, ale składa z nich odpowiedź. W praktyce oznacza to, że możesz mieć dobrą stronę i nawet niezłą pozycję, ale i tak nie być źródłem, które AI wybiera do odpowiedzi. Kluczowym mechanizmem, który za tym stoi, jest RAG (Retrieval-Augmented Generation). To podejście polega na tym, że zanim model wygeneruje odpowiedź, najpierw wyszukuje pasujące treści w bazie dokumentów, a dopiero potem je streszcza lub łączy w finalną odpowiedź.
Widoczność w AI = bycie „retrievable”, nie tylko „zoptymalizowanym”
W tym miejscu wchodzimy w sedno: dla systemów AI liczy się nie tylko to, czy strona zawiera dane słowo kluczowe. Liczy się, czy treść da się sprawnie „wydobyć” jako odpowiedni fragment i dopasować do intencji pytania. W dokumentacji Google ten proces jest opisywany jako współpraca dwóch etapów: retrieval i ranking — najpierw wyszukujemy kandydatów, a potem układamy ich według trafności. To przesuwa ciężar optymalizacji w stronę semantyki. Zamiast pytania „czy mamy w tekście frazę?”, pojawia się pytanie „czy nasz content jest najlepszą odpowiedzią na problem użytkownika — i czy system AI potrafi to rozpoznać?”.
Co to oznacza dla firm i marketerów?
W praktyce widoczność w AI Answers zaczyna być realnym źródłem ruchu i leadów, ale tylko wtedy, gdy treści są przygotowane w sposób, który wspiera trzy rzeczy:
- Dopasowanie znaczeniowe (embeddings, semantyka),
- Łatwe wydobywanie fragmentów (chunking i struktura),
- Trafność odpowiedzi (ranking / reranking).
To ważne rozróżnienie, bo embeddings potrafią świetnie mierzyć podobieństwo znaczeniowe, ale same w sobie nie zawsze odpowiadają na pytanie „czy dokument faktycznie udziela odpowiedzi”. Google wprost zwraca uwagę, że reranking może dać bardziej precyzyjny wynik niż same embeddingi, bo ocenia jakość odpowiedzi na zapytanie. I tu pojawia się biznesowy wniosek: nawet jeśli Twoja strona jest „o temacie”, to AI może uznać, że nie jest najlepszym materiałem do odpowiedzi i zacytować konkurencję, która ma lepszą strukturę, definicje, przykłady i bardziej „odpowiedziowy” content.
Właśnie dlatego SEO pod AI Answers to nie jest kolejny trend do odhaczenia, tylko zmiana standardu: trzeba projektować treści tak, aby były jednocześnie dobrze pozycjonujące się w Google i gotowe do wykorzystania przez modele AI.

Co to są embeddings i reprezentacje wektorowe
Embedding to reprezentacja tekstu (lub innego typu danych) w postaci wektora liczb, która zachowuje informację o znaczeniu. Innymi słowy: zamiast traktować słowa jak „ciąg znaków”, system AI zamienia je na liczby opisujące sens wypowiedzi, dzięki czemu potrafi porównywać treści semantycznie, a nie tylko po identycznych frazach.
Embedding w 1 zdaniu: definicja, którą AI łatwo cytuje
Embeddings to wektory znaczeń — numeryczne „odciski palca” tekstu, które pozwalają mierzyć podobieństwo między zapytaniem a treścią na podstawie sensu, a nie literalnego dopasowania słów.
Jak AI zamienia treść w wektor (bez wchodzenia w matematykę)
Proces wygląda prosto z perspektywy użytkownika, choć pod spodem dzieje się sporo. Model językowy bierze fragment tekstu i mapuje go do punktu w wielowymiarowej przestrzeni. Teksty o podobnym znaczeniu lądują „bliżej siebie”, a teksty o innym znaczeniu — „dalej”. To właśnie dlatego system potrafi uznać, że dwa różnie sformułowane zdania mówią o tym samym problemie i powinny zwrócić podobne wyniki.
W praktyce embeddings są wykorzystywane do tego, aby na etapie wyszukiwania (retrieval) szybko znaleźć dokumenty lub fragmenty treści, które „pasują znaczeniowo” do pytania użytkownika. Dopiero później — w zależności od systemu — wyniki są dodatkowo porządkowane i oceniane pod kątem tego, czy rzeczywiście odpowiadają na pytanie.
Dlaczego wektory „łapią znaczenie”, a nie tylko słowa
Klasyczne SEO przez lata bazowało na tym, że konkretne słowo kluczowe powinno pojawić się w strategicznych miejscach. W podejściu semantycznym ważniejsze staje się to, czy treść pokrywa temat w sposób spójny i odpowiada na intencję. Embeddings pomagają to mierzyć, bo potrafią rozpoznać bliskość znaczeniową nawet wtedy, gdy słownictwo jest inne.
Przykład z życia. Użytkownik może wpisać „optymalizacja treści pod AI answers”, a inny „jak pisać content, który AI cytuje”. To nie są identyczne frazy, ale sens jest bardzo zbliżony. Jeśli masz w artykule sekcję, która jasno tłumaczy mechanizm doboru źródeł przez systemy AI i podaje praktyczne zasady przygotowania treści, embeddings „zobaczą” podobieństwo i mogą podciągnąć Twoją stronę jako kandydata do odpowiedzi — nawet jeśli nie używasz dokładnie tej samej frazy w każdym akapicie.
Co to oznacza dla SEO i treści na stronie
Z perspektywy pozycjonowania oznacza to zmianę priorytetów. Nie chodzi o to, żeby upchnąć jak najwięcej wariantów słowa kluczowego. Chodzi o to, aby treść była semantycznie kompletna: zawierała definicje, wyjaśnienia „jak to działa”, przykłady oraz jednoznaczne odpowiedzi na pytania użytkowników. Taki content jest jednocześnie lepszy dla człowieka i łatwiejszy do wykorzystania przez systemy AI.
W kontekście sprzedażowym ma to bardzo konkretną konsekwencję: jeśli Twoje landing pages i artykuły nie są pisane „pod odpowiedzi”, to możesz tracić widoczność tam, gdzie użytkownik podejmuje decyzję — w gotowej odpowiedzi AI. Dlatego w Justidea w praktyce łączymy klasyczne SEO z projektowaniem treści pod semantykę i AI Search: od architektury informacji, przez strukturę sekcji, aż po optymalizację fragmentów, które mają największą szansę zostać zacytowane.
Wyszukiwanie wektorowe i semantyczne — jak AI dobiera treści do odpowiedzi
Wyszukiwanie wektorowe (vector search) to jeden z kluczowych mechanizmów stojących za tym, jak systemy AI dobierają treści do odpowiedzi. Zamiast sprawdzać, czy dana fraza występuje w tekście dosłownie, system porównuje podobieństwo znaczeniowe pomiędzy pytaniem użytkownika a fragmentami treści. To właśnie dlatego w erze AI coraz częściej wygrywają strony, które opisują temat szeroko i logicznie, a nie tylko „trafiają słowem kluczowym”.
Semantic SEO: optymalizacja pod znaczenie, encje i intencje
Semantic SEO to podejście, w którym skupiamy się na tym, co użytkownik chce osiągnąć (intencja) oraz jakie pojęcia i zależności są niezbędne, aby temat był wyjaśniony kompletnie. W praktyce nie chodzi więc o powtarzanie tej samej frazy w kilku wariantach, tylko o zbudowanie treści jako mapy pojęć: definicje, kontekst, przykłady, zastosowania, różnice między pojęciami i typowe pytania.
Wyszukiwarki i systemy AI coraz lepiej rozpoznają, czy strona pokrywa temat w sposób spójny, a także czy odpowiada na realne wątpliwości użytkownika. To podejście jest naturalnie zgodne z tym, jak działają embeddings: treści „bogate semantycznie” mają zwykle więcej punktów styku z zapytaniami i lepiej dopasowują się w porównaniu znaczeniowym.
Co sprawia, że strona jest „semantycznie trafna”
Jeśli mielibyśmy sprowadzić semantyczną trafność do jednego kryterium, brzmiałoby ono tak: czy po przeczytaniu tej treści użytkownik naprawdę ma odpowiedź i może przejść do działania? Z perspektywy AI oznacza to, że content powinien zawierać nie tylko ogólniki, ale też konkretne informacje, które da się wykorzystać w odpowiedzi.
W praktyce „semantycznie trafne” treści mają kilka wspólnych cech. Po pierwsze, bardzo szybko doprecyzowują, o czym jest temat, i ustawiają kontekst. Po drugie, rozbijają zagadnienie na logiczne sekcje, które da się cytować niezależnie od siebie. Po trzecie, przechodzą od definicji do praktyki: pokazują, jak temat wpływa na decyzje biznesowe, wdrożenia, procesy i wyniki.
Przykład: różne zapytania, ta sama intencja (AI łączy kropki)
Wyobraźmy sobie trzy zapytania:
- 1) „RAG SEO”
- 2) „jak AI wybiera źródła do odpowiedzi”
- 3) „optymalizacja treści pod AI Answers”
Na poziomie słów kluczowych to trzy różne tematy. Ale na poziomie intencji użytkownika jest to bardzo podobny problem: „chcę zrozumieć, jak działa mechanizm odpowiedzi AI i jak przygotować treści, żeby zwiększyć swoją widoczność”. Wyszukiwanie wektorowe pozwala systemowi to zauważyć, bo porównuje znaczenie, a nie tylko formę językową.
Dla SEO oznacza to ważną zmianę: jeden dobrze napisany artykuł, który kompletnie tłumaczy temat i podaje praktyczne wnioski, może zbierać widoczność na wiele różnych zapytań, nawet jeśli nie wszystkie zawierają te same frazy. Właśnie dlatego w strategiach opartych o semantykę często wygrywa topical completeness — czyli „pokrycie tematu do końca” — zamiast budowania dziesiątek cienkich podstron pod pojedyncze warianty słów kluczowych.
Co to oznacza dla strategii contentu i sprzedaży
W kontekście biznesowym wyszukiwanie wektorowe ma bardzo prostą konsekwencję: jeśli Twoje treści są pisane tylko pod klasyczne frazy i nie odpowiadają na intencje, to w AI Answers możesz być „niewidzialny” nawet wtedy, gdy w Google nadal masz sensowne pozycje. To szczególnie ważne w branżach, gdzie użytkownik szuka konkretnej rekomendacji, porównania lub instrukcji, a odpowiedź AI może stać się pierwszym miejscem kontaktu z marką.
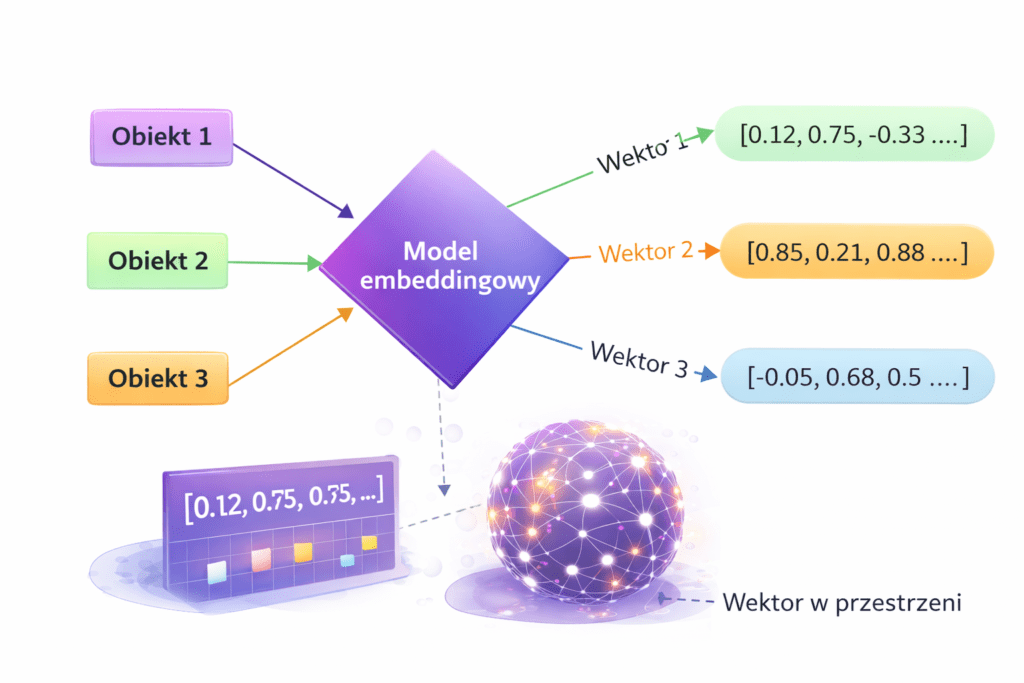
Przykład reprezentacji wektorowej w SEO i AI
RAG w praktyce — mechanizm, który decyduje, co AI zacytuje
Jeśli embeddings są „językiem”, którym AI opisuje znaczenie treści, to RAG jest mechanizmem, który decyduje, jakie źródła zostaną użyte do zbudowania odpowiedzi. Skrót RAG pochodzi od Retrieval-Augmented Generation i można go rozumieć jako podejście, w którym model AI najpierw wyszukuje pasujące informacje w dokumentach, a dopiero potem generuje odpowiedź na bazie znalezionego kontekstu.
Co to jest RAG i po co w ogóle istnieje
RAG to sposób łączenia wyszukiwania i generowania treści, dzięki któremu AI może odpowiadać na pytania w oparciu o konkretne źródła, a nie wyłącznie o „wiedzę” zapisaną w modelu. To ważne, bo w wielu zastosowaniach (zwłaszcza biznesowych) liczy się aktualność, precyzja i możliwość wskazania, skąd pochodzi informacja.
W kontekście SEO oznacza to jedno: Twoja treść może być nie tylko stroną do kliknięcia w wynikach wyszukiwania, ale też materiałem źródłowym, z którego systemy AI będą budowały odpowiedzi. Jeżeli jednak Twoje treści nie są łatwe do „wydobycia” i zrozumienia, model może je pominąć nawet wtedy, gdy są merytorycznie dobre.
Retrieval → ranking → generation: jak wygląda pipeline
W praktyce RAG można rozłożyć na trzy etapy. To rozpisanie jest bardzo ważne, bo pokazuje, gdzie SEO realnie wpływa na wynik:
| Etap | Co się dzieje | Co to oznacza dla treści SEO |
|---|---|---|
| Retrieval | System szuka najlepszych pasujących fragmentów treści na podstawie podobieństwa semantycznego. | Treść musi mieć jasne sekcje, definicje i fragmenty „samodzielne” znaczeniowo. |
| Ranking / reranking | Wyniki są porządkowane tak, aby wybrać te, które najlepiej odpowiadają na pytanie. | Wygrywają fragmenty, które wprost odpowiadają na pytanie, a nie tylko są „o temacie”. |
| Generation | Model składa odpowiedź na bazie wybranych fragmentów (czasem z cytowaniem źródeł). | Im bardziej jednoznaczny fragment, tym większa szansa, że zostanie zacytowany lub użyty. |
Warto zauważyć, że drugi etap bywa krytyczny. Sama bliskość semantyczna (embeddings) nie zawsze wystarcza, bo „podobne” nie znaczy „odpowiadające”. Dlatego systemy stosują reranking, który ocenia, czy dany fragment realnie rozwiązuje problem użytkownika.
Dlaczego RAG preferuje fragmenty (chunk-i), a nie całe artykuły
Jednym z najważniejszych powodów, dla których AI wybiera fragmenty zamiast całych stron, jest efektywność. Praca na krótszych kawałkach treści pozwala:
1) szybciej wyszukiwać pasujące informacje,
2) ograniczać „szum” (niepotrzebny kontekst),
3) budować odpowiedź z precyzyjnych bloków, które da się połączyć w spójną całość.
To tłumaczy, dlaczego świetnie zoptymalizowany artykuł może nadal nie być cytowany, jeśli nie ma w nim fragmentów, które są samodzielnymi odpowiedziami. AI nie „czyta” strony jak człowiek. AI częściej „wyciąga” konkretny blok treści, który najlepiej pasuje do pytania.
Przykład: blog vs landing page — co ma większą szansę trafić do odpowiedzi
Załóżmy, że użytkownik pyta: „Co to jest RAG i jak wpływa na SEO?”
Wariant A: artykuł blogowy ma sekcję z definicją, a zaraz pod nią krótkie wyjaśnienie mechanizmu (retrieval → ranking → generation) i 1 praktyczny wniosek dla SEO. Taki fragment jest „samodzielny” i bardzo łatwy do wykorzystania w odpowiedzi.
Wariant B: landing page usługi opisuje RAG dopiero po kilku akapitach marketingowych, bez definicji, a wyjaśnienie miesza RAG z kilkoma innymi pojęciami. W takim przypadku system może uznać, że trudno wyciągnąć z tego jednoznaczny fragment odpowiedzi i poszukać źródła gdzie indziej.
To nie znaczy, że landing page nie może być cytowalny. Może, ale musi mieć fragmenty, które są „odpowiedziowe” i osadzone w jasnym kontekście, a nie ukryte w ogólnym opisie oferty.
Przykład: jedno pytanie, kilka typów źródeł
Załóżmy inne pytanie: „Jak przygotować treść pod AI Answers?”
W systemach opartych o RAG często pojawia się taki schemat doboru kontekstu:
- • krótka definicja z artykułu edukacyjnego (co to jest AI Answers),
- • lista zasad z poradnika (jak pisać fragmenty do cytowania),
- • fragment z dokumentacji / analizy (dlaczego chunking i struktura mają znaczenie).
Dlatego strategicznie najlepsze są treści, które łączą te trzy elementy: definicje, mechanikę działania i praktyczne zastosowanie. Właśnie w takim układzie systemy AI najczęściej znajdują fragmenty, które nadają się do wykorzystania jako odpowiedź.
Wniosek: RAG nagradza treści, które odpowiadają „fragmentami”, nie ogólnikami
Jeżeli chcesz zwiększyć szansę, że Twoja strona będzie wykorzystywana jako źródło w AI Answers, musisz zacząć myśleć o treści jak o zbiorze fragmentów, które da się odzyskać i użyć w konkretnym kontekście. W kolejnych sekcjach przejdziemy przez elementy, które najbardziej wpływają na ten proces: chunking, dopasowanie semantyczne i różnicę między podobieństwem a realną trafnością odpowiedzi.
Chunking treści pod AI Answers — jak pisać, żeby AI wyciągało właściwe fragmenty
Jeśli RAG jest mechanizmem, który „buduje odpowiedź”, to chunking jest praktyką, która decyduje o tym, z czego ta odpowiedź może zostać złożona. W uproszczeniu: system AI bardzo często nie pracuje na całych artykułach, tylko na ich fragmentach. Dlatego struktura treści i sposób podziału na sekcje przestaje być wyłącznie kwestią wygody czytelnika, a staje się realnym czynnikiem wpływającym na widoczność w AI Answers.
Czym jest chunking (definicja do cytowania)
Chunking to dzielenie treści na mniejsze, logiczne fragmenty, które można łatwo porównać semantycznie z pytaniem użytkownika i odzyskać jako kontekst do odpowiedzi AI. Najlepsze chunk-i to takie, które „działają samodzielnie”: mają jasny temat, krótki kontekst i konkretną informację lub odpowiedź.
Dlaczego chunking jest krytyczny w RAG i AI Search
Systemy oparte o RAG muszą wykonać szybkie wyszukiwanie pasujących informacji w dużej liczbie dokumentów. Zamiast analizować każdą stronę w całości, dzielą treść na mniejsze bloki, tworzą dla nich embeddingi i dopiero potem sprawdzają, które fragmenty są najbardziej zbliżone do zapytania użytkownika. To podejście ma kilka konsekwencji. Po pierwsze, AI łatwiej znajduje konkretną odpowiedź, gdy jest ona zamknięta w jednym fragmencie. Po drugie, zbyt duże bloki rozmywają temat, a zbyt małe mogą tracić kontekst i przestają być jednoznaczne.
W praktyce chunking jest więc kompromisem między precyzją a kontekstem. Dobrze pocięta treść nie tylko poprawia możliwość znalezienia fragmentu, ale też ułatwia systemowi AI bezpieczne użycie go w odpowiedzi.
Typowe parametry chunkingu (widełki, które warto rozumieć)
W świecie narzędzi i wdrożeń często spotyka się dość podobne widełki, które pomagają utrzymać balans między jakością a kosztami przetwarzania. Warto je znać nawet wtedy, gdy nie wdrażasz RAG technicznie, bo te wartości mówią, jak „myśli” system dobierający kontekst.
| Parametr | Najczęściej spotykane widełki | Co się dzieje, gdy jest źle ustawiony |
|---|---|---|
| Rozmiar fragmentu | około 256–512 tokenów | Zbyt duży: miesza kilka tematów. Zbyt mały: gubi kontekst i jest niejednoznaczny. |
| Overlap (nakładanie) | około 10–20% | Brak overlapu: urywa definicje i myśli. Zbyt duży overlap: powtarzalność i „szum”. |
| Rodzaj podziału | sekcje / akapity / semantycznie | Mechaniczne cięcie może rozrywać logiczne części i psuć trafność retrieval. |
Te wartości nie są „magicznym przepisem”, ale dobrze opisują kierunek. Jeśli fragment ma odpowiadać na pytanie użytkownika, musi być wystarczająco krótki, aby trafić w sedno, i jednocześnie wystarczająco pełny, aby nie wymagał dopowiadania z innego miejsca.
3 strategie chunkingu i co oznaczają dla treści SEO
1) Fixed-size chunking (mechaniczny podział co X znaków)
To najprostsze podejście: system dzieli tekst co określoną długość. Technicznie jest szybkie, ale w contentach marketingowych i SEO bywa ryzykowne, bo potrafi rozciąć definicję w połowie lub rozdzielić przykład od wniosku.
2) Section-based / recursive chunking (podział po nagłówkach i strukturze)
To podejście jest znacznie bliższe temu, jak buduje się sensowny artykuł SEO. Każdy nagłówek H2/H3 i jego treść mogą tworzyć naturalny fragment tematyczny. Dla blogów i poradników to zwykle najlepsza baza, bo struktura treści jest spójna z intencją czytelnika.
3) Semantic chunking (podział według znaczenia)
To najbardziej „inteligentna” forma, gdzie system stara się wykrywać granice tematów i dzielić tekst w miejscach, w których naturalnie zmienia się wątek. Daje najlepsze dopasowanie w retrieval, ale wymaga więcej pracy lub lepszych narzędzi.
Przykład: ta sama treść, inna cytowalność
Załóżmy, że w artykule mamy długi blok zatytułowany „SEO pod AI Answers”, w którym opisujesz jednocześnie embeddings, RAG, chunking i reranking. Dla człowieka może to być „ok”, ale dla AI taki fragment jest zbyt szeroki, żeby stał się dobrą odpowiedzią na jedno konkretne pytanie.
Teraz drugi wariant: rozbijasz tę część na trzy krótkie sekcje:
• Co to jest RAG? (definicja + pipeline)
• Czym jest chunking? (definicja + praktyczne zasady)
• Embeddings vs reranking (różnica + wpływ na trafność)
W tym układzie AI może bardzo łatwo zacytować konkretną odpowiedź. Jeśli użytkownik pyta o RAG, system bierze fragment o RAG. Jeśli pyta o chunking, bierze fragment o chunkingu. Nie musi szukać kompromisu w jednym, zbyt szerokim bloku.
Jak pisać „retrieval-ready” content (praktyczne zasady dla SEO)
Dobre praktyki chunkingu w SEO można wdrożyć bez dotykania kodu czy baz wektorowych. To w dużej mierze kwestia redakcji i architektury informacji. Po pierwsze, każda sekcja powinna mieć jeden temat i wyraźną tezę. Po drugie, definicje warto pisać w pierwszych 1–2 zdaniach sekcji, bo to ułatwia odzyskanie fragmentu jako odpowiedzi. Po trzecie, dobrze działają krótkie przykłady, które zamykają myśl i pokazują zastosowanie.
W praktyce najlepiej działają akapity, które odpowiadają na pytanie użytkownika wprost. Jeśli tytuł sekcji brzmi „Czym jest chunking?”, to pierwsze zdania powinny rzeczywiście odpowiadać na to pytanie. Jeżeli zamiast tego zaczynasz od historii, dygresji lub ogólnych haseł, fragment staje się mniej jednoznaczny i trudniej go odzyskać w retrieval.
Najczęstsze błędy (które obniżają szansę na użycie treści w AI Answers)
W kontekście AI Answers powtarza się kilka typowych problemów. Pierwszym jest mieszanie tematów w jednej sekcji, przez co fragment nie odpowiada na jedno pytanie. Drugim jest brak definicji i konkretu — czyli sekcja „o czymś”, ale bez odpowiedzi. Trzecim jest zbyt duża objętość jednego bloku, w którym czytelnik musi sam „wyłowić” sedno, a AI często nie będzie miało po co sięgnąć.
Jeżeli potraktujesz strukturę treści jako zestaw fragmentów, które mają być odzyskiwane i wykorzystywane w odpowiedziach, wtedy chunking przestaje być technicznym detalem. Staje się przewagą strategiczną w SEO, bo zwiększa szansę, że to właśnie Twoja strona będzie źródłem, a nie tylko kolejnym wynikiem.
Cosine similarity — jak mierzyć dopasowanie znaczeniowe treści do intencji
W klasycznym SEO często porównujemy treść do słowa kluczowego w dość prosty sposób: sprawdzamy, czy fraza występuje w tytule, nagłówkach i tekście, a potem oceniamy, czy temat jest „pokryty”. W podejściu semantycznym pojawia się jednak dodatkowe pytanie: czy ta treść jest znaczeniowo podobna do tego, czego szuka użytkownik? I tu wchodzi cosine similarity — jedna z najpopularniejszych miar podobieństwa wektorowego, która pozwala ocenić, jak blisko siebie znajdują się dwa embeddingi.
Cosine similarity w 1 zdaniu (definicja do cytowania)
Cosine similarity mierzy, jak bardzo podobne znaczeniowo są dwa teksty, porównując kierunek ich wektorów (embeddingów) w przestrzeni semantycznej — im wynik bliższy 1, tym większe podobieństwo.
O co chodzi w cosine similarity (prosto i praktycznie)
Najważniejsze jest to, że cosine similarity nie patrzy na długość tekstu, tylko na „kierunek znaczenia”. Dzięki temu krótka odpowiedź może być bardzo podobna semantycznie do długiego artykułu, jeśli oba opisują ten sam problem. To świetnie pasuje do realiów AI Search, bo model często wybiera fragmenty (chunk-i), które odpowiadają na pytanie, nawet jeśli są krótkie.
W praktyce wygląda to tak: masz embedding zapytania (np. „jak przygotować treści pod AI answers”) i embedding fragmentu treści z Twojej strony. Cosine similarity mówi, na ile one są do siebie „podobne znaczeniowo”. Jeżeli wynik jest wysoki, fragment ma większą szansę zostać uznany za trafny kandydat w retrieval.
Jak interpretować wyniki (orientacyjnie)
Warto podejść do tego pragmatycznie. Nie istnieje jeden uniwersalny próg „dobry/zły” dla każdej branży i każdego modelu embeddingowego, ale można przyjąć robocze widełki, które pomagają w analizie:
| Cosine similarity | Jak to czytać | Co zwykle oznacza dla SEO |
|---|---|---|
| 0.00 – 0.30 | Niskie podobieństwo | Treść raczej nie odpowiada na intencję lub jest z innego tematu. |
| 0.30 – 0.55 | Umiarkowane podobieństwo | Coś „zahacza” temat, ale brakuje konkretu lub jest zbyt ogólnie. |
| 0.55 – 0.75 | Dobre dopasowanie | Treść jest tematycznie trafna, często wystarczy dopracować strukturę i odpowiedzi. |
| 0.75 – 0.90+ | Bardzo wysokie dopasowanie | Treść mocno odpowiada intencji i ma duży potencjał retrieval/cytowania. |
Te progi warto traktować jako punkt startowy do testów, a nie dogmat. W praktyce nawet treść z wysokim cosine similarity może nie być cytowana, jeśli nie odpowiada jasno na pytanie albo jest zbyt „rozlazła” w strukturze. To właśnie różnica między podobieństwem semantycznym a realną trafnością odpowiedzi, o której porozmawiamy w kolejnej sekcji.
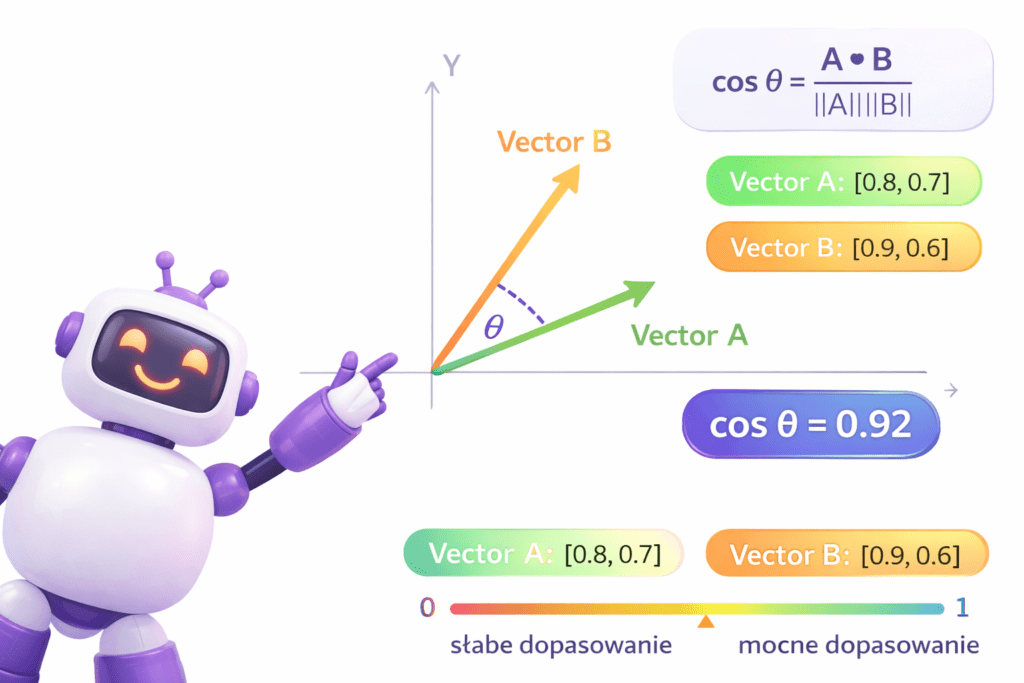
Przykład wizualizacji dopasowania kąta do odległości w kontekście cosine similarity
Jak użyć cosine similarity w SEO: 3 realne zastosowania
1) Audyt dopasowania sekcji do intencji
Możesz porównać embedding frazy (lub pytania) z embeddingami konkretnych sekcji strony. Jeśli widzisz, że np. sekcja „Jak działa RAG?” ma wynik 0.82, a sekcja „Chunking” tylko 0.46, to masz jasną wskazówkę, gdzie treść wymaga wzmocnienia, doprecyzowania definicji albo lepszego kontekstu.
Przykład: podstrona usługowa o „SEO pod AI” ma nagłówek o embeddings, ale opisuje je bardzo ogólnie. Cosine similarity względem zapytania „embeddings w SEO” jest umiarkowane (np. 0.51). Po dodaniu krótkiej definicji, przykładu i różnicy między embeddings a rerankingiem wynik może skoczyć do poziomu „dobrego dopasowania”, bo treść zaczyna realnie odpowiadać na pytanie.
2) Wykrywanie kanibalizacji semantycznej
W klasycznym ujęciu kanibalizacja to dwie strony, które „gryzą się” o tę samą frazę. W semantycznym ujęciu problem wygląda szerzej: dwie strony mogą nie mieć identycznych słów kluczowych, ale i tak opisywać to samo. Cosine similarity między treściami (lub ich sekcjami) pozwala zobaczyć, czy masz na stronie kilka materiałów o bardzo podobnym znaczeniu, które konkurują o ten sam zestaw intencji.
Przykład: jeden artykuł ma tytuł „RAG SEO”, a drugi „AI Answers i SEO”. Jeśli oba mają bardzo zbliżone sekcje o retrieval i chunkingu, mogą konkurować semantycznie. Czasem lepszym rozwiązaniem jest połączenie treści lub rozdzielenie tematów na różne intencje.
3) Linkowanie wewnętrzne oparte o znaczenie
W linkowaniu wewnętrznym często kierujemy się „ręcznym” dopasowaniem: wydaje nam się, że dwie podstrony są powiązane. Porównanie wektorowe pozwala podejść do tego metodycznie: jeśli dwie treści mają wysokie podobieństwo semantyczne, link jest naturalny i wspiera tematykę. Jeśli podobieństwo jest niskie, link może być sztuczny i rozmywa architekturę informacji.
Przykład: jak to wygląda na konkretnym pytaniu użytkownika
Załóżmy, że użytkownik pyta: „Jak przygotować content pod AI Answers?”
Masz trzy fragmenty na stronie:
A) sekcja o „AI Search” (ogólna, trendowa),
B) sekcja „Chunking treści” (konkretna, praktyczna),
C) sekcja „Embeddings vs reranking” (porównawcza).
W retrieval najczęściej wygra fragment B, bo odpowiada praktycznie na pytanie. Fragment A może mieć przyzwoite podobieństwo znaczeniowe, ale jest za ogólny. Fragment C może być wartościowy jako uzupełnienie kontekstu, ale nie jest pierwszym wyborem. To pokazuje, że cosine similarity dobrze wskazuje kierunek, ale ostatecznie liczy się to, czy fragment jest „odpowiedziowy”.
Wniosek: cosine similarity to narzędzie diagnostyczne, nie cel sam w sobie
Najlepszy sposób myślenia o cosine similarity w SEO jest taki: to miernik, który pozwala szybciej zlokalizować problemy z dopasowaniem treści do intencji. Jeżeli wynik jest niski, prawdopodobnie brakuje Ci kontekstu, definicji lub konkretnej odpowiedzi. Jeżeli wynik jest wysoki, masz dobry fundament, ale nadal musisz zadbać o to, aby fragment był jasny, jednoznaczny i łatwy do wykorzystania w odpowiedzi AI.
Embeddings vs reranking — dlaczego “podobne” nie zawsze znaczy “najlepsza odpowiedź”
Jeśli pracujesz z wyszukiwaniem semantycznym lub analizujesz treści pod AI Answers, bardzo szybko trafisz na zjawisko, które na pierwszy rzut oka wydaje się sprzeczne z logiką: fragment treści może mieć wysokie podobieństwo semantyczne do pytania użytkownika, a mimo to nie być najlepszą odpowiedzią. To właśnie moment, w którym wchodzi rozróżnienie między embeddings (podobieństwem znaczeniowym) a rerankingiem (oceną jakości odpowiedzi na pytanie).
Embeddings: szybkie znalezienie kandydatów podobnych znaczeniowo
Embeddings świetnie nadają się do etapu retrieval, czyli wyszukiwania „kandydatów” na odpowiedź. System porównuje wektor pytania z wektorami fragmentów treści i wybiera te, które są najbliżej znaczeniowo. To jest szybkie, skalowalne i dobrze działa nawet wtedy, gdy pytanie i treść są ujęte innymi słowami.
Problem polega na tym, że embeddings nie zawsze rozróżniają subtelne różnice pomiędzy fragmentem, który jest „o temacie”, a fragmentem, który faktycznie odpowiada na konkretne pytanie. W praktyce embeddings mogą uznać za podobne zarówno definicję, jak i ogólny opis, nawet jeśli użytkownik szuka instrukcji krok po kroku.
Reranking: wybór fragmentu, który realnie odpowiada na pytanie
Reranking to etap, w którym system bierze już wybrane fragmenty (kandydatów) i ocenia, które z nich najbardziej pasują do pytania użytkownika. Tu w grę wchodzi „jakość odpowiedzi”, a nie tylko podobieństwo znaczeniowe. W praktyce reranker może preferować fragment, który zawiera konkretne wyjaśnienie, definicję, przykład lub instrukcję, nawet jeśli jego embedding jest minimalnie mniej „blisko” zapytania niż inny fragment.
W dokumentacji i analizach dotyczących wyszukiwania semantycznego często podkreśla się, że reranking potrafi poprawić trafność wyników, bo działa jak filtr „czy to jest dobra odpowiedź?”, a nie tylko „czy to jest podobne?”.
Przykład: dwa fragmenty o RAG, ale tylko jeden odpowiada
Załóżmy, że użytkownik pyta: „Co to jest RAG?”
Masz dwa fragmenty na stronie:
Fragment A (ogólny):
„RAG to podejście łączące AI i wyszukiwanie, dzięki któremu systemy mogą generować odpowiedzi na podstawie danych.”
Fragment B (odpowiedziowy):
„RAG (Retrieval-Augmented Generation) to podejście, w którym AI najpierw wyszukuje pasujące fragmenty treści (retrieval), a dopiero potem generuje odpowiedź na ich podstawie (generation).”
Oba fragmenty są podobne znaczeniowo, więc embeddings mogą ocenić je bardzo wysoko. Ale z perspektywy użytkownika fragment B jest lepszą odpowiedzią: jest precyzyjny, definiuje skrót i tłumaczy mechanizm. Reranking często wybierze właśnie taki fragment, bo rozpoznaje, że jest „bardziej odpowiedziowy”.
Przykład z SEO: „Jak przygotować treści pod AI Answers?”
Załóżmy pytanie: „Jak przygotować treści pod AI Answers?”
Na stronie masz dwa pasujące bloki:
Fragment A (trendowy):
„AI Answers to przyszłość wyszukiwania, dlatego warto inwestować w nowoczesne treści i dbać o jakość contentu.”
Fragment B (praktyczny):
„Aby zwiększyć szansę na cytowanie w AI Answers, twórz sekcje z definicjami i krótkimi odpowiedziami, stosuj logiczny podział na fragmenty, a najważniejsze wnioski umieszczaj na początku sekcji.”
Znów: embeddings mogą uznać oba fragmenty za podobne, bo oba mówią o AI Answers i treściach. Ale reranking prawie zawsze preferuje fragment B, bo zawiera konkretne zasady. I to jest dokładnie ten moment, w którym treść przestaje być „opisem tematu”, a staje się odpowiedzią.
Co to oznacza dla SEO: pisz pod pytania, nie pod pojęcia
Najważniejszy wniosek z rozróżnienia embeddings vs reranking jest bardzo praktyczny. Jeśli chcesz, aby Twoje treści były wybierane do odpowiedzi AI, muszą spełnić dwa warunki jednocześnie:
1) muszą być semantycznie trafne (embeddings muszą je „złapać”),
2) muszą być odpowiedziowe (reranking musi je uznać za najlepszy fragment).
To w praktyce przesuwa sposób pisania treści. Nie wystarczy mieć sekcję „o RAG”. Trzeba mieć sekcję, która odpowiada: co to jest RAG, jak działa i co to zmienia. Nie wystarczy mieć stronę „o AI SEO”. Trzeba mieć fragmenty, które odpowiadają na realne pytania użytkowników: „jak przygotować content”, „co wpływa na cytowanie”, „jak dzielić tekst”, „co jest ważniejsze: definicja czy przykład”.
Mini-checklista: jak pisać fragmenty, które wygrywają reranking
Jeśli chcesz, aby Twoje fragmenty były wybierane nie tylko przez embeddings, ale też przez reranking, warto pilnować kilku zasad. Najpierw odpowiedz na pytanie wprost w pierwszych zdaniach sekcji. Następnie dodaj krótkie wyjaśnienie mechanizmu. Na końcu dorzuć przykład albo wniosek praktyczny. Taki układ jest czytelny dla człowieka i jednocześnie maksymalnie „odpowiedziowy” dla systemu.
W kolejnej części przejdziemy do tego, jak zwiększyć szansę cytowania treści w AI Answers w sposób systemowy: od struktury, przez semantyczne pokrycie tematu, aż po elementy, które pomagają budować wiarygodność i kontekst.
Jak zwiększyć szansę, że AI zacytuje Twoją treść
To, czy Twoja treść zostanie wykorzystana jako źródło w AI Answers, rzadko zależy od jednego czynnika. Zwykle jest to suma drobnych decyzji: jak zbudowana jest struktura, czy sekcje odpowiadają na pytania, czy pojęcia są doprecyzowane, a także czy treść zawiera elementy, które zwiększają wiarygodność i jednoznaczność. Poniżej znajdziesz praktyczne zasady, które realnie poprawiają „cytowalność” treści w systemach opartych o retrieval i RAG.
1) Pisz „entity-first” — czyli o pojęciach i zależnościach, nie tylko o frazach
Modele AI i wyszukiwarki działające semantycznie lepiej rozumieją treści, które są zbudowane wokół encji (konkretnych pojęć, obiektów, procesów) oraz relacji między nimi. W praktyce oznacza to, że zamiast skupiać się na jednym słowie kluczowym, warto jasno zdefiniować najważniejsze pojęcia i pokazać, jak się ze sobą łączą.
Przykład: jeśli temat to „SEO pod AI Answers”, w treści powinny pojawić się i zostać wyjaśnione powiązane encje, takie jak embeddings, wyszukiwanie wektorowe, retrieval, chunking, reranking oraz intencja użytkownika. Dzięki temu fragmenty tekstu są nie tylko o „AI SEO”, ale też mają semantyczne punkty zaczepienia, które ułatwiają systemowi dopasowanie ich do pytań.
2) Odpowiadaj wprost na pytania użytkownika (w pierwszych zdaniach sekcji)
Jedna z najprostszych zasad, która działa zaskakująco dobrze: jeśli nagłówek sugeruje pytanie, to pierwsze zdania powinny zawierać odpowiedź. W systemach retrieval często wygrywają fragmenty, które są jednoznaczne i „samowystarczalne”. Jeśli sekcja zaczyna się od dygresji lub zbyt ogólnego wstępu, to fragment traci swoje właściwości jako gotowa odpowiedź.
Przykład: nagłówek „Co to jest RAG?” powinien w pierwszym akapicie zawierać definicję z rozwinięciem skrótu, a dopiero potem analogię i rozwinięcie. Wtedy nawet jeśli system pobierze tylko 2–3 zdania, nadal ma pełną odpowiedź.
3) Buduj sekcje jako samodzielne „bloki wiedzy”
W AI Answers liczą się fragmenty, które można wyciągnąć bez kontekstu całego artykułu. Dlatego dobrze sprawdzają się sekcje, które mają wewnętrzną strukturę: definicja → mechanizm → przykład → wniosek. To idealny układ zarówno pod człowieka, jak i pod retrieval.
Przykład: w sekcji o chunkingu sama definicja nie wystarczy. Lepszy fragment do cytowania to taki, który dopowiada „po co” i „jak to wpływa na odpowiedzi AI”. Wtedy AI nie musi dodawać własnych założeń i chętniej użyje Twojego tekstu jako źródła.
4) Dodawaj przykłady, które zamykają sens (i nie są zbyt ogólne)
Przykłady działają jak „kotwice znaczenia”. AI łatwiej dopasowuje fragmenty, które nie tylko coś opisują, ale też pokazują zastosowanie w realnej sytuacji. Dla czytelnika to również moment, w którym teoria zamienia się w praktykę.
Przykład: zamiast zdania „AI wybiera najbardziej trafne źródła”, lepiej działa krótkie doprecyzowanie: „Jeśli użytkownik pyta ‘jak dzielić treść pod AI Answers’, system częściej wybierze fragment z konkretnymi zasadami chunkingu niż ogólną sekcję o trendach AI”.
5) Stosuj krótkie podsumowania w stylu „wniosek:”
Jedno zdanie podsumowania na końcu sekcji często robi dużą różnicę. Dla użytkownika to szybkie streszczenie, a dla AI to świetny fragment do użycia w odpowiedzi. Warto, aby takie zdania były konkretne, a nie „motywacyjne”.
Przykład podsumowania: „W praktyce AI cytuje te treści, które są zbudowane z krótkich, jednoznacznych fragmentów odpowiadających na konkretne pytania użytkowników.”
6) Utrzymuj „topical completeness”, ale bez lania wody
Treści cytowane przez AI często mają jedną cechę: pokrywają temat kompletnie, ale robią to w sposób uporządkowany. Zbyt krótki tekst bywa niepełny, zbyt długi może być rozmyty. Dlatego najlepiej działa układ, w którym każdy wątek ma swoją sekcję, ale sekcje są zwarte i konkretne.
Przykład: zamiast robić jeden duży rozdział „AI w SEO”, lepiej rozdzielić temat na RAG, embeddings, chunking i reranking. Dzięki temu użytkownik łatwiej znajduje odpowiedź, a AI ma gotowe fragmenty do retrieval.
7) Używaj sygnałów wiarygodności: definicje, precyzja i spójność
W kontekście AI Search wiarygodność treści nie opiera się wyłącznie na „autorytecie domeny”. Liczy się też to, czy fragmenty są precyzyjne, jednoznaczne i spójne. Jeśli w jednym miejscu używasz pojęcia „vector search”, a w innym „semantic search”, ale bez wyjaśnienia relacji między nimi, fragment staje się mniej stabilny znaczeniowo.
Przykład: jeśli wprowadzasz termin „reranking”, dopowiedz w dwóch zdaniach, że to etap oceny trafności odpowiedzi wśród kandydatów zwróconych przez embeddings. Taki fragment jest dużo łatwiejszy do cytowania i trudniej go błędnie zinterpretować.
Wniosek: cytowalność to efekt struktury i jakości „fragmentów odpowiedzi”
W praktyce nie wygrywają treści, które są tylko „ładnie napisane” albo „napakowane słowami kluczowymi”. Wygrywają te, które są zorganizowane jak zestaw gotowych odpowiedzi: mają definicje, przykłady, jasne wnioski i logiczną strukturę. Jeśli potraktujesz swój content jak źródło, z którego AI ma brać fragmenty, łatwiej będzie Ci projektować artykuły i landing pages, które nie tylko rankują w Google, ale też mają realną szansę stać się częścią odpowiedzi AI.
7 zastosowań embeddings i RAG w SEO (dla biznesu, nie tylko dla geeków)
Embeddings i RAG często kojarzą się z rozwiązaniami „dla inżynierów”, ale w praktyce są bardzo użyteczne również w klasycznych procesach SEO. Co ważne, nie chodzi tu o futurystyczne wdrożenia, tylko o konkretne sposoby, jak lepiej planować content, oceniać dopasowanie treści do intencji i budować strukturę strony tak, aby była czytelna zarówno dla ludzi, jak i dla systemów AI. Poniżej znajdziesz 7 zastosowań, które najczęściej da się przełożyć na realną poprawę widoczności.
1) Audyt treści pod AI Search i luki semantyczne
W klasycznym audycie SEO często sprawdzamy, czy treść ma odpowiednie nagłówki, odpowiednią długość i czy zawiera podstawowe elementy. Podejście semantyczne pozwala pójść krok dalej: sprawdzić, czy treść ma „pełne pokrycie znaczeniowe” względem intencji użytkownika. Jeśli porównasz sekcje swojej strony do zestawu pytań lub tematów, szybko zobaczysz, gdzie brakuje definicji, wyjaśnienia mechanizmu albo praktycznych przykładów.
Przykład: podstrona o „SEO pod AI” opisuje, że AI zmienia wyszukiwanie, ale nie ma sekcji o chunkingu ani o różnicy embeddings vs reranking. W takim przypadku treść może być „o temacie”, ale nie jest kompletna semantycznie dla użytkownika szukającego praktycznej odpowiedzi.
2) Clustering tematów i planowanie contentu pod topical authority
Embeddings świetnie działają do grupowania tematów, bo potrafią łączyć zapytania podobne znaczeniowo nawet wtedy, gdy brzmią inaczej. Dzięki temu można budować klastry tematyczne oparte o intencję, a nie tylko o wspólne słowa.
Przykład: frazy „RAG SEO”, „AI Answers a pozycjonowanie” i „jak AI cytuje treści” mogą trafić do jednego klastra, bo dotyczą tego samego problemu. To pozwala stworzyć jeden mocny materiał (pillar) i kilka artykułów wspierających zamiast 10 stron o zbyt wąskim zakresie.
3) Wykrywanie kanibalizacji semantycznej
Kanibalizacja nie zawsze wygląda jak konflikt o identyczne słowo kluczowe. Często dwie podstrony konkurują o podobne intencje, mimo że używają innego języka. Porównanie semantyczne treści pozwala znaleźć sytuacje, w których masz kilka materiałów „o tym samym”, a system nie wie, który jest ważniejszy.
Przykład: artykuł „Co to jest RAG SEO” i artykuł „Jak pisać pod AI Search” mają bardzo podobne fragmenty o retrieval i chunkingu. Jeśli oba rankują na podobne zapytania, możesz rozważyć lepsze rozdzielenie intencji albo wzmocnienie jednego jako głównego źródła.
4) Dobór linkowania wewnętrznego na podstawie znaczenia
Linkowanie wewnętrzne jest skuteczniejsze, gdy łączy treści, które naprawdę są powiązane intencją. W podejściu semantycznym można to oceniać nie tylko „na czuja”, ale też przez podobieństwo znaczeniowe pomiędzy stronami lub sekcjami.
Przykład: jeśli masz poradnik o AI Answers i osobny materiał o „wyszukiwaniu semantycznym”, link między nimi jest naturalny, bo użytkownik prawdopodobnie chce zrozumieć bazę techniczną. Natomiast link do treści ogólnej „co to jest SEO” może rozmywać temat i nie wnosić nic w kontekście intencji.
5) Kontrola spójności landingów usługowych (czy AI rozumie, co sprzedajesz)
To zastosowanie jest często niedoceniane. Landing może mieć dobre SEO, ale jeśli jest napisany nieprecyzyjnie, systemy AI mogą mieć problem z jednoznacznym zrozumieniem, co dokładnie oferujesz. Semantyczna analiza pomaga wychwycić, czy strona ma jasne definicje usług, zakres, kontekst i różnice względem innych ofert.
Przykład: jeśli na stronie usługi „SEO pod AI” mieszasz pojęcia typu „AI marketing”, „automatyzacja”, „copywriting AI” i „pozycjonowanie”, bez jasnych granic, treść jest semantycznie rozmyta. Z perspektywy AI to może być sygnał, że strona nie jest najlepszym źródłem do cytowania w pytaniach o RAG czy embeddings.
6) Rekomendacje rozbudowy treści na bazie brakujących „bloków odpowiedzi”
W praktyce bardzo często nie trzeba pisać wszystkiego od nowa. Wystarczy dołożyć brakujące bloki, które domykają temat. To mogą być krótkie fragmenty: definicja, przykład, checklista lub sekcja „najczęstsze błędy”. To właśnie takie elementy zwiększają szanse na retrieval i cytowanie.
Przykład: w artykule o AI Search brakuje krótkiej odpowiedzi na pytanie „dlaczego AI bierze fragmenty, a nie całe artykuły?”. Dodanie 5–7 zdań wyjaśnienia o chunkingu może znacząco zwiększyć wartość artykułu i jego użyteczność w odpowiedziach AI.
7) Budowa baz wiedzy i FAQ gotowych pod AI Answers
Bazy wiedzy, poradniki i sekcje FAQ to formaty, które świetnie „pasują” do retrieval, bo są naturalnie zbudowane z krótkich pytań i odpowiedzi. Jeśli chcesz, aby Twoja marka była cytowana, takie treści są często najbardziej efektywną drogą, bo dostarczają gotowych fragmentów, które AI może wykorzystać bez interpretacji.
Przykład: zamiast jednego długiego artykułu o „AI SEO” można stworzyć także serię krótkich materiałów: „co to jest RAG”, „co to są embeddings”, „jak działa reranking”, „jak przygotować content do cytowania”. Każdy z nich może być samodzielnym źródłem, a razem budują topical authority.
Podsumowanie: embeddings i RAG dają praktyczne narzędzia do lepszego SEO
Największa przewaga podejścia semantycznego polega na tym, że łączy analitykę z praktyką. Z jednej strony możesz lepiej planować content i strukturę strony, a z drugiej szybciej diagnozować, dlaczego treść nie odpowiada na intencję użytkownika. W kolejnym kroku przejdziemy do krótkiej checklisty „AI-ready SEO”, która pozwala ocenić, czy treść ma realną szansę być użyta w odpowiedziach AI.
Checklista “AI-ready SEO” dla firm (szybki audyt)
W świecie AI Answers i wyszukiwania semantycznego łatwo wpaść w pułapkę myślenia, że potrzebujesz skomplikowanych wdrożeń technicznych, aby poprawić widoczność. W praktyce wiele problemów da się zdiagnozować prostą checklistą. Jeśli Twoje treści nie są „AI-ready”, to najczęściej nie dlatego, że brakuje Ci technologii, tylko dlatego, że brakuje Ci jasnych bloków odpowiedzi, spójnej struktury i semantycznej kompletności.
Poniższa checklista działa jak szybki audyt. Możesz przejść ją dla artykułu blogowego, landing page’a usługowego, kategorii e-commerce albo bazy wiedzy. Najlepiej czytać ją tak: jeżeli w kilku punktach masz „nie”, to właśnie tam są największe szanse na poprawę widoczności w AI Answers.
1) Czy treść odpowiada na pytania użytkownika wprost (bez dygresji)?
Najbardziej cytowalne fragmenty to te, które zaczynają się od odpowiedzi. Jeśli nagłówek brzmi jak pytanie („Co to jest RAG?”), to pierwszy akapit powinien zawierać definicję, a dopiero potem rozwinięcie. W przeciwnym razie fragment staje się mniej jednoznaczny, a AI częściej wybierze źródło, które odpowiada prościej i szybciej.
Przykład testu: weź pierwszy akapit pod nagłówkiem H2/H3 i sprawdź, czy po jego przeczytaniu użytkownik zna odpowiedź. Jeśli nie — sekcja wymaga przebudowy.
2) Czy każda sekcja ma jeden temat i da się ją cytować niezależnie?
W AI Search fragmenty działają jak „klocki”, które można odzyskać i użyć jako kontekst. Jeśli jedna sekcja miesza trzy różne wątki, retrieval może działać gorzej, bo system nie wie, co w tym fragmencie jest najważniejsze. Najlepiej, jeśli każda sekcja ma jasny temat i prowadzi czytelnika od definicji do wniosku.
Przykład testu: jeśli masz sekcję „AI w SEO”, która mówi jednocześnie o embeddings, RAG, chunkingu i narzędziach, lepiej rozdzielić ją na kilka mniejszych bloków.
3) Czy w treści są „bloki odpowiedzi” (definicje, zasady, wnioski)?
Treść cytowalna to treść, z której można wyjąć konkret. Dlatego świetnie działają: definicje w 1–2 zdaniach, krótkie zasady (jak coś zrobić) oraz jednozdaniowe wnioski na końcu sekcji. Bez takich bloków artykuł może być poprawny, ale nie będzie „odpowiedziowy”.
Przykład testu: spróbuj znaleźć w artykule 3 zdania, które mogłyby być cytowane jako gotowa odpowiedź. Jeśli jest to trudne, brakuje Ci fragmentów o wysokiej gęstości informacji.
4) Czy treść ma semantyczne pokrycie tematu (topical completeness)?
AI i wyszukiwarki semantyczne preferują treści, które domykają temat. To nie znaczy „pisz najdłużej”, tylko „nie pomijaj kluczowych elementów”. Jeżeli użytkownik szuka informacji o RAG SEO, to zwykle oczekuje, że dowie się: czym jest RAG, jak działa retrieval, dlaczego chunking jest ważny i co robi reranking. Jeśli część tych elementów nie występuje, treść wygląda na niepełną.
Przykład testu: wypisz 5–7 pojęć, które są niezbędne dla tematu, i sprawdź, czy są w treści wyjaśnione, a nie tylko wspomniane.
5) Czy przykłady w treści są konkretne i osadzone w realnym scenariuszu?
Przykłady budują jednoznaczność. AI łatwiej dopasowuje fragment, który pokazuje zastosowanie. Najlepsze przykłady nie są „ogólne”, tylko odnoszą się do realnych sytuacji: landing page, artykuł blogowy, pytanie użytkownika, decyzja zakupowa, porównanie narzędzi.
Przykład testu: jeśli Twoje przykłady mogłyby pasować do dowolnej branży i dowolnego tematu, to zwykle są zbyt ogólne. Dobrze, gdy przykład jest “z życia SEO”.
6) Czy struktura treści wspiera chunking (krótkie i logiczne fragmenty)?
Chunking nie oznacza, że musisz dzielić tekst na mikrosekwencje. Chodzi o to, aby fragmenty były logiczne: akapity nie powinny być ogromne, sekcje powinny mieć jasne tematy, a najważniejsze informacje powinny pojawiać się blisko nagłówka. To zwiększa szansę, że system odzyska właściwy fragment i wykorzysta go jako kontekst do odpowiedzi.
Przykład testu: jeśli jedna sekcja H2 ma 15 akapitów i omawia kilka tematów, AI może odzyskać fragment przypadkowo lub wcale.
7) Czy masz jednoznaczne sygnały wiarygodności i spójności pojęć?
W semantycznym świecie brak spójności terminologii potrafi osłabić treść. Jeśli używasz kilku pojęć na to samo (np. „AI Search”, „answer engines”, „AI answers”), warto pokazać, że to powiązane koncepcje i doprecyzować różnice. Podobnie z terminami typu embeddings, retrieval, reranking. Krótkie dopowiedzenia sprawiają, że treść jest stabilniejsza i mniej podatna na błędną interpretację.
Przykład testu: jeśli czytelnik musi się domyślać, czy „wyszukiwanie semantyczne” to to samo co „wyszukiwanie wektorowe”, warto doprecyzować w 2 zdaniach relację między pojęciami.
Wynik audytu: szybka tabela oceny
Jeśli chcesz podejść do tego metodycznie, możesz ocenić każdą kategorię w skali 0–2. To proste, ale pomaga szybko określić priorytety.
| Obszar | 0 | 1 | 2 |
|---|---|---|---|
| Odpowiedziowość | Brak odpowiedzi wprost | Częściowo | Odpowiedzi na start sekcji |
| Struktura i chunking | Chaotyczna | Średnia | Logiczne bloki wiedzy |
| Topical completeness | Braki tematów | Większość pokryta | Temat domknięty |
| Przykłady i praktyka | Brak przykładów | Pojedyncze | Konkretne scenariusze |
| Spójność pojęć | Niejasna | OK | Jednoznaczna |
Jeżeli w większości obszarów masz 2, Twoja treść jest dobrze przygotowana pod AI Answers. Jeśli w kilku punktach pojawiają się zera, to sygnał, że problem leży nie w „braku AI”, tylko w strukturze i jakości fragmentów. W podsumowaniu zbierzemy to w konkretne wnioski: co warto zrobić szybko, a co zaplanować jako strategię.
Checklista “AI-ready SEO” dla firm (szybki audyt)
W świecie AI Answers i wyszukiwania semantycznego łatwo wpaść w pułapkę myślenia, że potrzebujesz skomplikowanych wdrożeń technicznych, aby poprawić widoczność. W praktyce wiele problemów da się zdiagnozować prostą checklistą. Jeśli Twoje treści nie są „AI-ready”, to najczęściej nie dlatego, że brakuje Ci technologii, tylko dlatego, że brakuje Ci jasnych bloków odpowiedzi, spójnej struktury i semantycznej kompletności.
Poniższa checklista działa jak szybki audyt. Możesz przejść ją dla artykułu blogowego, landing page’a usługowego, kategorii e-commerce albo bazy wiedzy. Najlepiej czytać ją tak: jeżeli w kilku punktach masz „nie”, to właśnie tam są największe szanse na poprawę widoczności w AI Answers.
1) Czy treść odpowiada na pytania użytkownika wprost (bez dygresji)?
Najbardziej cytowalne fragmenty to te, które zaczynają się od odpowiedzi. Jeśli nagłówek brzmi jak pytanie („Co to jest RAG?”), to pierwszy akapit powinien zawierać definicję, a dopiero potem rozwinięcie. W przeciwnym razie fragment staje się mniej jednoznaczny, a AI częściej wybierze źródło, które odpowiada prościej i szybciej.
Przykład testu: weź pierwszy akapit pod nagłówkiem H2/H3 i sprawdź, czy po jego przeczytaniu użytkownik zna odpowiedź. Jeśli nie — sekcja wymaga przebudowy.
2) Czy każda sekcja ma jeden temat i da się ją cytować niezależnie?
W AI Search fragmenty działają jak „klocki”, które można odzyskać i użyć jako kontekst. Jeśli jedna sekcja miesza trzy różne wątki, retrieval może działać gorzej, bo system nie wie, co w tym fragmencie jest najważniejsze. Najlepiej, jeśli każda sekcja ma jasny temat i prowadzi czytelnika od definicji do wniosku.
Przykład testu: jeśli masz sekcję „AI w SEO”, która mówi jednocześnie o embeddings, RAG, chunkingu i narzędziach, lepiej rozdzielić ją na kilka mniejszych bloków.
3) Czy w treści są „bloki odpowiedzi” (definicje, zasady, wnioski)?
Treść cytowalna to treść, z której można wyjąć konkret. Dlatego świetnie działają: definicje w 1–2 zdaniach, krótkie zasady (jak coś zrobić) oraz jednozdaniowe wnioski na końcu sekcji. Bez takich bloków artykuł może być poprawny, ale nie będzie „odpowiedziowy”.
Przykład testu: spróbuj znaleźć w artykule 3 zdania, które mogłyby być cytowane jako gotowa odpowiedź. Jeśli jest to trudne, brakuje Ci fragmentów o wysokiej gęstości informacji.
4) Czy treść ma semantyczne pokrycie tematu (topical completeness)?
AI i wyszukiwarki semantyczne preferują treści, które domykają temat. To nie znaczy „pisz najdłużej”, tylko „nie pomijaj kluczowych elementów”. Jeżeli użytkownik szuka informacji o RAG SEO, to zwykle oczekuje, że dowie się: czym jest RAG, jak działa retrieval, dlaczego chunking jest ważny i co robi reranking. Jeśli część tych elementów nie występuje, treść wygląda na niepełną.
Przykład testu: wypisz 5–7 pojęć, które są niezbędne dla tematu, i sprawdź, czy są w treści wyjaśnione, a nie tylko wspomniane.
5) Czy przykłady w treści są konkretne i osadzone w realnym scenariuszu?
Przykłady budują jednoznaczność. AI łatwiej dopasowuje fragment, który pokazuje zastosowanie. Najlepsze przykłady nie są „ogólne”, tylko odnoszą się do realnych sytuacji: landing page, artykuł blogowy, pytanie użytkownika, decyzja zakupowa, porównanie narzędzi.
Przykład testu: jeśli Twoje przykłady mogłyby pasować do dowolnej branży i dowolnego tematu, to zwykle są zbyt ogólne. Dobrze, gdy przykład jest “z życia SEO”.
6) Czy struktura treści wspiera chunking (krótkie i logiczne fragmenty)?
Chunking nie oznacza, że musisz dzielić tekst na mikrosekwencje. Chodzi o to, aby fragmenty były logiczne: akapity nie powinny być ogromne, sekcje powinny mieć jasne tematy, a najważniejsze informacje powinny pojawiać się blisko nagłówka. To zwiększa szansę, że system odzyska właściwy fragment i wykorzysta go jako kontekst do odpowiedzi.
Przykład testu: jeśli jedna sekcja H2 ma 15 akapitów i omawia kilka tematów, AI może odzyskać fragment przypadkowo lub wcale.
7) Czy masz jednoznaczne sygnały wiarygodności i spójności pojęć?
W semantycznym świecie brak spójności terminologii potrafi osłabić treść. Jeśli używasz kilku pojęć na to samo (np. „AI Search”, „answer engines”, „AI answers”), warto pokazać, że to powiązane koncepcje i doprecyzować różnice. Podobnie z terminami typu embeddings, retrieval, reranking. Krótkie dopowiedzenia sprawiają, że treść jest stabilniejsza i mniej podatna na błędną interpretację.
Przykład testu: jeśli czytelnik musi się domyślać, czy „wyszukiwanie semantyczne” to to samo co „wyszukiwanie wektorowe”, warto doprecyzować w 2 zdaniach relację między pojęciami.
Wynik audytu: szybka tabela oceny
Jeśli chcesz podejść do tego metodycznie, możesz ocenić każdą kategorię w skali 0–2. To proste, ale pomaga szybko określić priorytety.
| Obszar | 0 | 1 | 2 |
|---|---|---|---|
| Odpowiedziowość | Brak odpowiedzi wprost | Częściowo | Odpowiedzi na start sekcji |
| Struktura i chunking | Chaotyczna | Średnia | Logiczne bloki wiedzy |
| Topical completeness | Braki tematów | Większość pokryta | Temat domknięty |
| Przykłady i praktyka | Brak przykładów | Pojedyncze | Konkretne scenariusze |
| Spójność pojęć | Niejasna | OK | Jednoznaczna |
Jeżeli w większości obszarów masz 2, Twoja treść jest dobrze przygotowana pod AI Answers. Jeśli w kilku punktach pojawiają się zera, to sygnał, że problem leży nie w „braku AI”, tylko w strukturze i jakości fragmentów. W podsumowaniu zbierzemy to w konkretne wnioski: co warto zrobić szybko, a co zaplanować jako strategię.
Nowa widoczność = Google + AI Answers
Wyszukiwanie wchodzi w etap, w którym treści konkurują nie tylko o pozycję w rankingu Google, ale także o to, czy staną się źródłem odpowiedzi w systemach AI. W praktyce oznacza to zmianę sposobu myślenia o content marketingu i SEO: wygrywają materiały, które są nie tylko „o temacie”, ale są zbudowane z fragmentów, które da się odzyskać i wykorzystać jako konkretne odpowiedzi.
Najważniejsze mechanizmy, które to napędzają, są dość spójne. Embeddings pomagają systemom AI dopasować pytanie do treści semantycznie, wyszukiwanie wektorowe pozwala szybko znaleźć kandydatów, RAG składa odpowiedź na bazie odzyskanego kontekstu, a reranking wybiera te fragmenty, które rzeczywiście odpowiadają na pytanie. Dlatego w praktyce „optymalizacja pod AI Answers” nie polega na dopisywaniu kilku fraz, tylko na projektowaniu treści w sposób uporządkowany i odpowiedziowy.
Co możesz wdrożyć szybko (bez zmiany całej strategii)
Jeżeli chcesz poprawić „AI-ready” charakter treści bez rewolucji na stronie, warto zacząć od rzeczy, które mają największy wpływ na retrieval i cytowalność. Uporządkowanie sekcji, dopisanie definicji w pierwszych zdaniach nagłówków, rozbicie zbyt długich bloków na logiczne fragmenty oraz dodanie krótkich przykładów to poprawki, które zwykle wnoszą najwięcej wartości przy najmniejszym koszcie. To również jeden z powodów, dla których tak dobrze działa podejście „sekcja po sekcji”: każdą część można wzmocnić tak, by była samodzielnym blokiem odpowiedzi.
Co warto traktować jako strategię (żeby zbudować przewagę)
Jeśli celujesz w trwałą przewagę, najważniejsze jest budowanie treści w modelu semantycznym: klastrów tematycznych opartych o intencje, a nie wyłącznie o frazy. W praktyce oznacza to planowanie tematów jako mapy zależności (np. RAG → chunking → embeddings → reranking), porządkowanie architektury informacji i rozwijanie materiałów tak, aby „domykały temat” zamiast powielać te same ogólniki w kilku artykułach.
To podejście jest korzystne również dla klasycznego SEO, bo treści semantycznie kompletne często rankują na wiele wariantów zapytań, a nie tylko na jedno słowo kluczowe. Dodatkowo w naturalny sposób budują topical authority i zwiększają szanse, że użytkownik wróci do strony jako do źródła wiedzy.
Najważniejsza myśl na koniec
AI nie premiuje „najbardziej zoptymalizowanych” treści — premiuje te, które najłatwiej zamienić w odpowiedź. Jeśli Twoje materiały mają jasne definicje, logiczne sekcje, praktyczne przykłady i wnioski, rośnie szansa, że będą dobrze działać zarówno w Google, jak i w AI Answers.
W kolejnej kolejności warto spojrzeć na swoje treści dokładnie tak, jak robią to systemy retrieval: jako na zbiór fragmentów, które powinny być jednoznaczne i użyteczne samodzielnie. To właśnie ta zmiana perspektywy sprawia, że „SEO pod AI Answers” przestaje być hasłem, a staje się realnym procesem budowania widoczności.
Bibliografia / źródła
- Google Cloud — materiały o wyszukiwaniu semantycznym i rerankingu (Vertex AI / Search)
- Databricks — poradniki i praktyki dotyczące chunkingu i RAG
- IBM — opracowania dotyczące RAG (Retrieval-Augmented Generation) i działania retrieval
- Pinecone — materiały o embeddings i vector databases (vector search)
- Search Engine Land / branżowe analizy zmian w wyszukiwaniu i wpływu AI na SEO
Sprawdź również:
- Vibe coding – czym jest i jak działa nowe podejście do programowania z AI?
- Link building w kontekście AI – jak sztuczna inteligencja zmienia zasady gry SEO
- Nano Banana – wszystko, co musisz wiedzieć o edytorze obrazów w Gemini
- Jak AI wspiera działania SEO?
- Czym jest Perplexity AI? Funkcje i zastosowania
- Google AI mode w Polsce – nowa era wyszukiwania informacji





















